Por Jose R. Zapata

En base a las herramientas actuales para el desarrollo de proyectos y productos de Ciencia de datos y Machine Learning, se recomienda el uso de Python, sin embargo, R es una herramienta muy poderosa para el análisis de datos y la visualización de los mismos.
Puede aprender python en el curso de Ciencia de Datos con Python.
Tidyverse
El tidyverse es una colección de paquetes R diseñados para ciencia de datos. Todos los paquetes comparten una filosofía de diseño subyacente, gramática y estructuras de datos.
El libro online R for Data Science muestra todas las facultades del tydiverse en ciencia de datos.
| Paquete | Descripción |
|---|---|
| dplyr | Manipulación de datos |
| tidyr | Ordenar datos (data wrangling) |
| ggplot2 | Visualización de datos |
| readr | Importar datos |
| purrr | Programación Funcional |
| tibble | tibbles, una nueva forma de dataframe |
| stringr | strings |
| forcats | factors, variable categóricas |
Instalar e importar Tidyverse
install.packages("tidyverse")
library(tidyverse)
El mundo de tidyverse es:
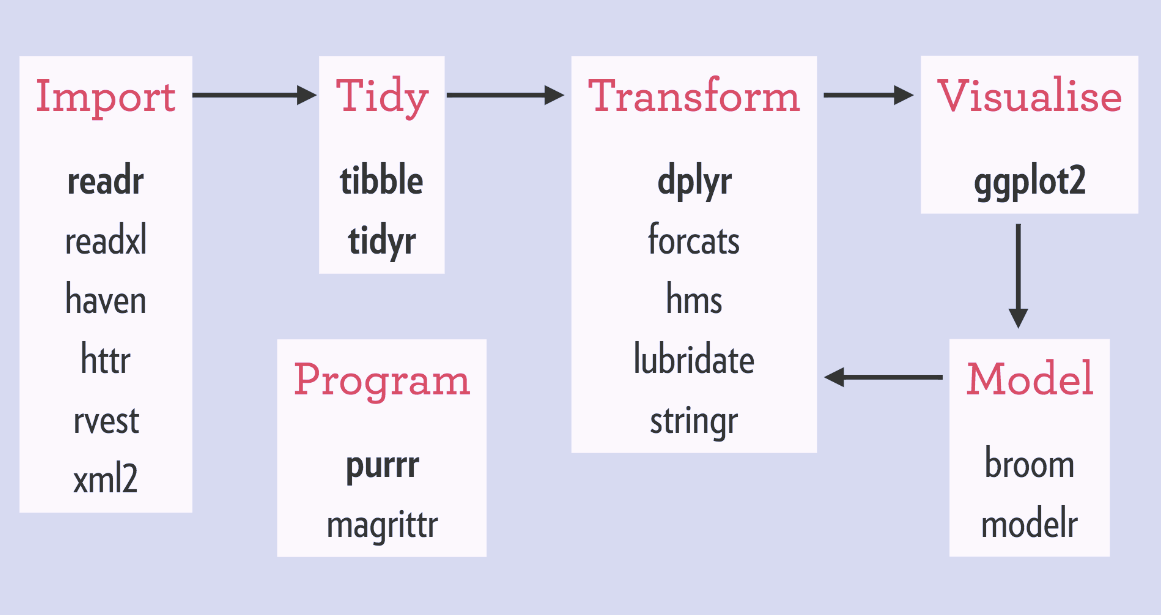
Manipulacion de datos (dplyr)
Documentacion en: https://cran.r-project.org/web/packages/dplyr/dplyr.pdf
- filter() (and slice())
- arrange()
- select() (and rename())
- distinct()
- mutate() (and transmute())
- summarise()
- sample_n() and sample_frac()
Instalacion de dplyr
# si ya esta instalado el tydiverse no es necesario instalarla
# Instalacion en R
#install.packages('dplyr')
# Llamar la libreria
library(dplyr)
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
Datos de ejemplo
# se puede descargar la base de datos nycflights13
# si ya esta instalado no hay necesidad de instalarlo nuevamente
install.packages('nycflights13',repos = 'http://cran.us.r-project.org')
Installing package into ‘/usr/local/lib/R/site-library’
(as ‘lib’ is unspecified)
library(nycflights13)
summary(flights)
year month day dep_time sched_dep_time
Min. :2013 Min. : 1.000 Min. : 1.00 Min. : 1 Min. : 106
1st Qu.:2013 1st Qu.: 4.000 1st Qu.: 8.00 1st Qu.: 907 1st Qu.: 906
Median :2013 Median : 7.000 Median :16.00 Median :1401 Median :1359
Mean :2013 Mean : 6.549 Mean :15.71 Mean :1349 Mean :1344
3rd Qu.:2013 3rd Qu.:10.000 3rd Qu.:23.00 3rd Qu.:1744 3rd Qu.:1729
Max. :2013 Max. :12.000 Max. :31.00 Max. :2400 Max. :2359
NA's :8255
dep_delay arr_time sched_arr_time arr_delay
Min. : -43.00 Min. : 1 Min. : 1 Min. : -86.000
1st Qu.: -5.00 1st Qu.:1104 1st Qu.:1124 1st Qu.: -17.000
Median : -2.00 Median :1535 Median :1556 Median : -5.000
Mean : 12.64 Mean :1502 Mean :1536 Mean : 6.895
3rd Qu.: 11.00 3rd Qu.:1940 3rd Qu.:1945 3rd Qu.: 14.000
Max. :1301.00 Max. :2400 Max. :2359 Max. :1272.000
NA's :8255 NA's :8713 NA's :9430
carrier flight tailnum origin
Length:336776 Min. : 1 Length:336776 Length:336776
Class :character 1st Qu.: 553 Class :character Class :character
Mode :character Median :1496 Mode :character Mode :character
Mean :1972
3rd Qu.:3465
Max. :8500
dest air_time distance hour
Length:336776 Min. : 20.0 Min. : 17 Min. : 1.00
Class :character 1st Qu.: 82.0 1st Qu.: 502 1st Qu.: 9.00
Mode :character Median :129.0 Median : 872 Median :13.00
Mean :150.7 Mean :1040 Mean :13.18
3rd Qu.:192.0 3rd Qu.:1389 3rd Qu.:17.00
Max. :695.0 Max. :4983 Max. :23.00
NA's :9430
minute time_hour
Min. : 0.00 Min. :2013-01-01 05:00:00.00
1st Qu.: 8.00 1st Qu.:2013-04-04 13:00:00.00
Median :29.00 Median :2013-07-03 10:00:00.00
Mean :26.23 Mean :2013-07-03 05:22:54.64
3rd Qu.:44.00 3rd Qu.:2013-10-01 07:00:00.00
Max. :59.00 Max. :2013-12-31 23:00:00.00
# Observe que el dataframe es muy largo
dim(flights)
- 336776
- 19
filter()
Permite seleccionar un subconjunto de filas en un dataframe. El primer argumento es el nombre. El segundo y siguientes argumentos son las expresiones que filtran el dataframe: por ejemplo, podemos seleccionar todos los vuelos del 3 de noviembre que fueron de American Airlines (AA) con:
head(filter(flights,month==11,day==3,carrier=='AA'))
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 11 | 3 | 538 | 545 | -7 | 824 | 855 | -31 | AA | 2243 | N5DWAA | JFK | MIA | 144 | 1089 | 5 | 45 | 2013-11-03 05:00:00 |
| 2013 | 11 | 3 | 556 | 600 | -4 | 900 | 905 | -5 | AA | 1175 | N3CSAA | LGA | MIA | 148 | 1096 | 6 | 0 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 604 | 610 | -6 | 844 | 855 | -11 | AA | 1103 | N3KDAA | LGA | DFW | 192 | 1389 | 6 | 10 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 624 | 629 | -5 | 907 | 929 | -22 | AA | 1205 | N3EJAA | EWR | MIA | 141 | 1085 | 6 | 29 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 625 | 630 | -5 | 736 | 805 | -29 | AA | 303 | N4WJAA | LGA | ORD | 113 | 733 | 6 | 30 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 653 | 655 | -2 | 925 | 920 | 5 | AA | 1263 | N634AA | JFK | LAS | 306 | 2248 | 6 | 55 | 2013-11-03 06:00:00 |
Es mucho mas simple que de la forma normal de R
head(flights[flights$month == 11 & flights$day == 3 & flights$carrier == 'AA', ])
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 11 | 3 | 538 | 545 | -7 | 824 | 855 | -31 | AA | 2243 | N5DWAA | JFK | MIA | 144 | 1089 | 5 | 45 | 2013-11-03 05:00:00 |
| 2013 | 11 | 3 | 556 | 600 | -4 | 900 | 905 | -5 | AA | 1175 | N3CSAA | LGA | MIA | 148 | 1096 | 6 | 0 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 604 | 610 | -6 | 844 | 855 | -11 | AA | 1103 | N3KDAA | LGA | DFW | 192 | 1389 | 6 | 10 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 624 | 629 | -5 | 907 | 929 | -22 | AA | 1205 | N3EJAA | EWR | MIA | 141 | 1085 | 6 | 29 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 625 | 630 | -5 | 736 | 805 | -29 | AA | 303 | N4WJAA | LGA | ORD | 113 | 733 | 6 | 30 | 2013-11-03 06:00:00 |
| 2013 | 11 | 3 | 653 | 655 | -2 | 925 | 920 | 5 | AA | 1263 | N634AA | JFK | LAS | 306 | 2248 | 6 | 55 | 2013-11-03 06:00:00 |
slice()
slice(flights, 1:4)
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 1 | 1 | 517 | 515 | 2 | 830 | 819 | 11 | UA | 1545 | N14228 | EWR | IAH | 227 | 1400 | 5 | 15 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 533 | 529 | 4 | 850 | 830 | 20 | UA | 1714 | N24211 | LGA | IAH | 227 | 1416 | 5 | 29 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 542 | 540 | 2 | 923 | 850 | 33 | AA | 1141 | N619AA | JFK | MIA | 160 | 1089 | 5 | 40 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 544 | 545 | -1 | 1004 | 1022 | -18 | B6 | 725 | N804JB | JFK | BQN | 183 | 1576 | 5 | 45 | 2013-01-01 05:00:00 |
arrange()
Funciona de manera similar a filter() excepto que en lugar de filtrar o seleccionar filas, las reordena. Se necesita un dataframe y un conjunto de nombres de columna (o expresiones más complicadas) para ordenar. Si proporciona más de un nombre de columna, cada columna adicional se utilizará para romper relaciones de los valores de las columnas anteriores:
head(arrange(flights,year,month,day,air_time))
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 1 | 1 | 2302 | 2200 | 62 | 2342 | 2253 | 49 | EV | 4276 | N13903 | EWR | BDL | 24 | 116 | 22 | 0 | 2013-01-01 22:00:00 |
| 2013 | 1 | 1 | 1318 | 1322 | -4 | 1358 | 1416 | -18 | EV | 4106 | N19554 | EWR | BDL | 25 | 116 | 13 | 22 | 2013-01-01 13:00:00 |
| 2013 | 1 | 1 | 2116 | 2110 | 6 | 2202 | 2212 | -10 | EV | 4404 | N15912 | EWR | PVD | 28 | 160 | 21 | 10 | 2013-01-01 21:00:00 |
| 2013 | 1 | 1 | 2000 | 2000 | 0 | 2054 | 2110 | -16 | 9E | 3664 | N836AY | JFK | PHL | 30 | 94 | 20 | 0 | 2013-01-01 20:00:00 |
| 2013 | 1 | 1 | 2056 | 2004 | 52 | 2156 | 2112 | 44 | EV | 4170 | N12540 | EWR | ALB | 31 | 143 | 20 | 4 | 2013-01-01 20:00:00 |
| 2013 | 1 | 1 | 908 | 915 | -7 | 1004 | 1033 | -29 | US | 1467 | N959UW | LGA | PHL | 32 | 96 | 9 | 15 | 2013-01-01 09:00:00 |
Se puede agregar desc() para ordenarlas en orden descendente
head(arrange(flights,desc(dep_delay)))
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 1 | 9 | 641 | 900 | 1301 | 1242 | 1530 | 1272 | HA | 51 | N384HA | JFK | HNL | 640 | 4983 | 9 | 0 | 2013-01-09 09:00:00 |
| 2013 | 6 | 15 | 1432 | 1935 | 1137 | 1607 | 2120 | 1127 | MQ | 3535 | N504MQ | JFK | CMH | 74 | 483 | 19 | 35 | 2013-06-15 19:00:00 |
| 2013 | 1 | 10 | 1121 | 1635 | 1126 | 1239 | 1810 | 1109 | MQ | 3695 | N517MQ | EWR | ORD | 111 | 719 | 16 | 35 | 2013-01-10 16:00:00 |
| 2013 | 9 | 20 | 1139 | 1845 | 1014 | 1457 | 2210 | 1007 | AA | 177 | N338AA | JFK | SFO | 354 | 2586 | 18 | 45 | 2013-09-20 18:00:00 |
| 2013 | 7 | 22 | 845 | 1600 | 1005 | 1044 | 1815 | 989 | MQ | 3075 | N665MQ | JFK | CVG | 96 | 589 | 16 | 0 | 2013-07-22 16:00:00 |
| 2013 | 4 | 10 | 1100 | 1900 | 960 | 1342 | 2211 | 931 | DL | 2391 | N959DL | JFK | TPA | 139 | 1005 | 19 | 0 | 2013-04-10 19:00:00 |
select()
Cuando se tiene grandes conjuntos de datos con muchas columnas, pero solo unos pocos se necesitan. select() permite crear rápidamente un subconjunto útil utilizando operaciones que generalmente solo funcionan en posiciones de variables numéricas:
head(select(flights,carrier))
| carrier |
|---|
| <chr> |
| UA |
| UA |
| AA |
| B6 |
| DL |
| UA |
rename()
Para renombrar las columnas, Esta no es una operacion “in-place”
head(rename(flights,airline_car = carrier))
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | airline_car | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 1 | 1 | 517 | 515 | 2 | 830 | 819 | 11 | UA | 1545 | N14228 | EWR | IAH | 227 | 1400 | 5 | 15 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 533 | 529 | 4 | 850 | 830 | 20 | UA | 1714 | N24211 | LGA | IAH | 227 | 1416 | 5 | 29 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 542 | 540 | 2 | 923 | 850 | 33 | AA | 1141 | N619AA | JFK | MIA | 160 | 1089 | 5 | 40 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 544 | 545 | -1 | 1004 | 1022 | -18 | B6 | 725 | N804JB | JFK | BQN | 183 | 1576 | 5 | 45 | 2013-01-01 05:00:00 |
| 2013 | 1 | 1 | 554 | 600 | -6 | 812 | 837 | -25 | DL | 461 | N668DN | LGA | ATL | 116 | 762 | 6 | 0 | 2013-01-01 06:00:00 |
| 2013 | 1 | 1 | 554 | 558 | -4 | 740 | 728 | 12 | UA | 1696 | N39463 | EWR | ORD | 150 | 719 | 5 | 58 | 2013-01-01 05:00:00 |
distinct()
Un uso común de select() es encontrar los valores de un conjunto de variables. Esto es particularmente útil junto con el verbo distinct() que solo devuelve los valores únicos en una tabla.
distinct(select(flights,carrier))
| carrier |
|---|
| <chr> |
| UA |
| AA |
| B6 |
| DL |
| EV |
| MQ |
| US |
| WN |
| VX |
| FL |
| AS |
| 9E |
| F9 |
| HA |
| YV |
| OO |
mutate()
Además de seleccionar conjuntos de columnas existentes, a menudo es útil agregar nuevas columnas que son funciones de columnas existentes. Este es el trabajo de mutate():
head(mutate(flights, new_col = arr_delay-dep_delay))
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | new_col |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> | <dbl> |
| 2013 | 1 | 1 | 517 | 515 | 2 | 830 | 819 | 11 | UA | 1545 | N14228 | EWR | IAH | 227 | 1400 | 5 | 15 | 2013-01-01 05:00:00 | 9 |
| 2013 | 1 | 1 | 533 | 529 | 4 | 850 | 830 | 20 | UA | 1714 | N24211 | LGA | IAH | 227 | 1416 | 5 | 29 | 2013-01-01 05:00:00 | 16 |
| 2013 | 1 | 1 | 542 | 540 | 2 | 923 | 850 | 33 | AA | 1141 | N619AA | JFK | MIA | 160 | 1089 | 5 | 40 | 2013-01-01 05:00:00 | 31 |
| 2013 | 1 | 1 | 544 | 545 | -1 | 1004 | 1022 | -18 | B6 | 725 | N804JB | JFK | BQN | 183 | 1576 | 5 | 45 | 2013-01-01 05:00:00 | -17 |
| 2013 | 1 | 1 | 554 | 600 | -6 | 812 | 837 | -25 | DL | 461 | N668DN | LGA | ATL | 116 | 762 | 6 | 0 | 2013-01-01 06:00:00 | -19 |
| 2013 | 1 | 1 | 554 | 558 | -4 | 740 | 728 | 12 | UA | 1696 | N39463 | EWR | ORD | 150 | 719 | 5 | 58 | 2013-01-01 05:00:00 | 16 |
transmutate()
Use transmute() si solo quieres las nuevas columnas:
head(transmute(flights, new_col = arr_delay-dep_delay))
| new_col |
|---|
| <dbl> |
| 9 |
| 16 |
| 31 |
| -17 |
| -19 |
| 16 |
summarize()
Puede usar summarize() para contraer rápidamente dataframes en filas individuales utilizando funciones que agregan resultados. Recuerde usar na.rm = TRUE para eliminar los valores de NA.
summarise(flights,avg_air_time=mean(air_time,na.rm=TRUE))
| avg_air_time |
|---|
| <dbl> |
| 150.6865 |
sample_n() y sample_frac()
Sirven para tomar una muestra aleatoria de filas: use sample_n() para un número fijo y sample_frac() para una fracción fija.
sample_n(flights,5)
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 5 | 12 | 1615 | 1555 | 20 | 1724 | 1726 | -2 | UA | 1492 | N37468 | EWR | ORD | 106 | 719 | 15 | 55 | 2013-05-12 15:00:00 |
| 2013 | 4 | 26 | 1430 | 1435 | -5 | 1553 | 1611 | -18 | UA | 1136 | N77295 | EWR | CLE | 65 | 404 | 14 | 35 | 2013-04-26 14:00:00 |
| 2013 | 5 | 6 | 1442 | 1440 | 2 | 1744 | 1740 | 4 | UA | 224 | N402UA | EWR | MIA | 158 | 1085 | 14 | 40 | 2013-05-06 14:00:00 |
| 2013 | 6 | 1 | 1621 | 1610 | 11 | 1733 | 1750 | -17 | 9E | 3410 | N919XJ | JFK | BOS | 39 | 187 | 16 | 10 | 2013-06-01 16:00:00 |
| 2013 | 8 | 2 | 1740 | 1735 | 5 | 2059 | 2030 | 29 | AA | 145 | N3DRAA | JFK | SAN | 330 | 2446 | 17 | 35 | 2013-08-02 17:00:00 |
# .002% de los datos
sample_frac(flights,0.00002) # USE replace=TRUE para el muestreo de inicio
| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <dbl> | <int> | <int> | <dbl> | <chr> | <int> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dttm> |
| 2013 | 8 | 3 | 1051 | 1055 | -4 | 1230 | 1235 | -5 | MQ | 3466 | N735MQ | LGA | RDU | 64 | 431 | 10 | 55 | 2013-08-03 10:00:00 |
| 2013 | 11 | 25 | 1633 | 1635 | -2 | 1756 | 1825 | -29 | AA | 343 | N527AA | LGA | ORD | 123 | 733 | 16 | 35 | 2013-11-25 16:00:00 |
| 2013 | 8 | 6 | 1107 | 1115 | -8 | 1310 | 1305 | 5 | MQ | 3281 | N723MQ | LGA | CMH | 76 | 479 | 11 | 15 | 2013-08-06 11:00:00 |
| 2013 | 12 | 27 | 1657 | 1659 | -2 | 1847 | 1901 | -14 | DL | 2076 | N977AT | EWR | DTW | 86 | 488 | 16 | 59 | 2013-12-27 16:00:00 |
| 2013 | 10 | 21 | 752 | 800 | -8 | 848 | 908 | -20 | US | 2138 | N945UW | LGA | BOS | 37 | 184 | 8 | 0 | 2013-10-21 08:00:00 |
| 2013 | 3 | 2 | 2005 | 2005 | 0 | 2245 | 2330 | -45 | VX | 415 | N637VA | JFK | LAX | 318 | 2475 | 20 | 5 | 2013-03-02 20:00:00 |
| 2013 | 2 | 24 | 819 | 825 | -6 | 922 | 945 | -23 | MQ | 4418 | N825MQ | JFK | DCA | 44 | 213 | 8 | 25 | 2013-02-24 08:00:00 |
Ordenar datos o data wrangling con tidyr
tidyr, que es un paquete complementario que ayuda a crear conjuntos de datos ordenados. La información ordenada es cuando tenemos un conjunto de datos donde cada fila es una observación y cada columna es una variable, de esta manera los datos están organizados de tal manera que cada celda es un valor para una variable específica de una observación específica. Tener los datos en este formato le ayudará a comprenderlos y permitirá analizarlos o visualizarlos de manera rápida y eficiente.
Instalar tidyr
# si ya esta instalado tidyverse no es necesario
#install.packages('tidyr',repos = 'http://cran.us.r-project.org')
library(tidyr)
library(data.table)
Attaching package: ‘data.table’
The following objects are masked from ‘package:dplyr’:
between, first, last
Data.frames vs data.tables
Todos los datatables también son data.frames. En términos generales, puede pensar en data.tables como data.frames con características adicionales. data.frame es parte de la base R. data.table es un paquete que amplía data.frames. Dos de sus características más notables son la velocidad y la sintaxis más limpia. Sin embargo, esa sintaxis para un data.table es diferente de la sintaxis R estándar para data.frame, mientras que para el ojo no entrenado es difícil distinguirlo de un vistazo. Por lo tanto, si lee un fragmento de código y no hay otro contexto para indicar que está trabajando con data.tables e intenta aplicar el código a un data.frame, puede fallar o producir resultados inesperados. Entonces, ¿cuáles son algunas de las diferencias prácticas? Éstos son algunos:
- operaciones mucho más rápidas y muy intuitivas.
- No imprimirá accidentalmente un gran data.frame con la necesidad de presionar Ctrl-C, data.table previene este tipo de accidente
Usar tidyr
gather()spread()separate()unite()
Datos de ejemplo
Datos de ejemplo para ser limpiados usando tidyr
comp <- c(1,1,1,2,2,2,3,3,3)
yr <- c(1998,1999,2000,1998,1999,2000,1998,1999,2000)
q1 <- runif(9, min=0, max=100)
q2 <- runif(9, min=0, max=100)
q3 <- runif(9, min=0, max=100)
q4 <- runif(9, min=0, max=100)
df <- data.frame(comp=comp,year=yr,Qtr1 = q1,Qtr2 = q2,Qtr3 = q3,Qtr4 = q4)
df
| comp | year | Qtr1 | Qtr2 | Qtr3 | Qtr4 |
|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 1 | 1998 | 33.923013 | 20.79095 | 76.6580703 | 36.900506 |
| 1 | 1999 | 66.145333 | 86.45187 | 39.1306662 | 55.764761 |
| 1 | 2000 | 62.354262 | 55.80614 | 18.1325816 | 82.780112 |
| 2 | 1998 | 81.845846 | 90.97619 | 70.2689152 | 63.980738 |
| 2 | 1999 | 93.780384 | 92.02719 | 0.9617078 | 75.756686 |
| 2 | 2000 | 2.084715 | 67.25328 | 41.5309248 | 44.093997 |
| 3 | 1998 | 99.420873 | 38.06650 | 17.2360717 | 4.275985 |
| 3 | 1999 | 52.786550 | 59.92561 | 58.9366497 | 71.895343 |
| 3 | 2000 | 87.184595 | 89.66924 | 81.8666423 | 48.470458 |
gather()
Son operaciones analogas a las pivot tables.
La función gather() colapsará múltiples columnas en valores de par de claves. El data.frame anterior se considera amplio ya que la variable de tiempo (representada como trimestres) está estructurada de manera que cada trimestre representa una variable. Para reestructurar el componente de tiempo como una variable individual, podemos reunir cada trimestre dentro de una variable de columna y también reunir los valores asociados con cada trimestre en una segunda variable de columna.
# Usando solo la funcion
a<- gather(df,Quarter,Revenue,Qtr1:Qtr4)
head(a)
| comp | year | Quarter | Revenue | |
|---|---|---|---|---|
| <dbl> | <dbl> | <chr> | <dbl> | |
| 1 | 1 | 1998 | Qtr1 | 33.923013 |
| 2 | 1 | 1999 | Qtr1 | 66.145333 |
| 3 | 1 | 2000 | Qtr1 | 62.354262 |
| 4 | 2 | 1998 | Qtr1 | 81.845846 |
| 5 | 2 | 1999 | Qtr1 | 93.780384 |
| 6 | 2 | 2000 | Qtr1 | 2.084715 |
spread()
Es el complemento de gather()
spread(a,Quarter,Revenue)
| comp | year | Qtr1 | Qtr2 | Qtr3 | Qtr4 |
|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 1 | 1998 | 33.923013 | 20.79095 | 76.6580703 | 36.900506 |
| 1 | 1999 | 66.145333 | 86.45187 | 39.1306662 | 55.764761 |
| 1 | 2000 | 62.354262 | 55.80614 | 18.1325816 | 82.780112 |
| 2 | 1998 | 81.845846 | 90.97619 | 70.2689152 | 63.980738 |
| 2 | 1999 | 93.780384 | 92.02719 | 0.9617078 | 75.756686 |
| 2 | 2000 | 2.084715 | 67.25328 | 41.5309248 | 44.093997 |
| 3 | 1998 | 99.420873 | 38.06650 | 17.2360717 | 4.275985 |
| 3 | 1999 | 52.786550 | 59.92561 | 58.9366497 | 71.895343 |
| 3 | 2000 | 87.184595 | 89.66924 | 81.8666423 | 48.470458 |
separate()
Dada la expresión regular o un vector de posiciones de caracteres, separate() convierte una sola columna de caracteres en múltiples columnas.
df <- data.frame(x = c(NA, "a.x", "b.y", "c.z"))
df
| x |
|---|
| <chr> |
| NA |
| a.x |
| b.y |
| c.z |
separate(df,x, c("ABC", "XYZ"))
| ABC | XYZ |
|---|---|
| <chr> | <chr> |
| NA | NA |
| a | x |
| b | y |
| c | z |
unite()
Unite es una función para pegar varias columnas en una sola.
head(mtcars)
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
| Valiant | 18.1 | 6 | 225 | 105 | 2.76 | 3.460 | 20.22 | 1 | 0 | 3 | 1 |
unidos <-unite(mtcars, "vs.am", c("vs","am"),sep = '.')
head(unidos)
| mpg | cyl | disp | hp | drat | wt | qsec | vs.am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <chr> | <dbl> | <dbl> | |
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.620 | 16.46 | 0.1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.875 | 17.02 | 0.1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.320 | 18.61 | 1.1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1.0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.440 | 17.02 | 0.0 | 3 | 2 |
| Valiant | 18.1 | 6 | 225 | 105 | 2.76 | 3.460 | 20.22 | 1.0 | 3 | 1 |
separate()
Separate() es el complemento de unite()
separate(unidos,vs.am, c("vs", "am"))
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <chr> | <chr> | <dbl> | <dbl> | |
| Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360.0 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
| Valiant | 18.1 | 6 | 225.0 | 105 | 2.76 | 3.460 | 20.22 | 1 | 0 | 3 | 1 |
| Duster 360 | 14.3 | 8 | 360.0 | 245 | 3.21 | 3.570 | 15.84 | 0 | 0 | 3 | 4 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Merc 230 | 22.8 | 4 | 140.8 | 95 | 3.92 | 3.150 | 22.90 | 1 | 0 | 4 | 2 |
| Merc 280 | 19.2 | 6 | 167.6 | 123 | 3.92 | 3.440 | 18.30 | 1 | 0 | 4 | 4 |
| Merc 280C | 17.8 | 6 | 167.6 | 123 | 3.92 | 3.440 | 18.90 | 1 | 0 | 4 | 4 |
| Merc 450SE | 16.4 | 8 | 275.8 | 180 | 3.07 | 4.070 | 17.40 | 0 | 0 | 3 | 3 |
| Merc 450SL | 17.3 | 8 | 275.8 | 180 | 3.07 | 3.730 | 17.60 | 0 | 0 | 3 | 3 |
| Merc 450SLC | 15.2 | 8 | 275.8 | 180 | 3.07 | 3.780 | 18.00 | 0 | 0 | 3 | 3 |
| Cadillac Fleetwood | 10.4 | 8 | 472.0 | 205 | 2.93 | 5.250 | 17.98 | 0 | 0 | 3 | 4 |
| Lincoln Continental | 10.4 | 8 | 460.0 | 215 | 3.00 | 5.424 | 17.82 | 0 | 0 | 3 | 4 |
| Chrysler Imperial | 14.7 | 8 | 440.0 | 230 | 3.23 | 5.345 | 17.42 | 0 | 0 | 3 | 4 |
| Fiat 128 | 32.4 | 4 | 78.7 | 66 | 4.08 | 2.200 | 19.47 | 1 | 1 | 4 | 1 |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Toyota Corolla | 33.9 | 4 | 71.1 | 65 | 4.22 | 1.835 | 19.90 | 1 | 1 | 4 | 1 |
| Toyota Corona | 21.5 | 4 | 120.1 | 97 | 3.70 | 2.465 | 20.01 | 1 | 0 | 3 | 1 |
| Dodge Challenger | 15.5 | 8 | 318.0 | 150 | 2.76 | 3.520 | 16.87 | 0 | 0 | 3 | 2 |
| AMC Javelin | 15.2 | 8 | 304.0 | 150 | 3.15 | 3.435 | 17.30 | 0 | 0 | 3 | 2 |
| Camaro Z28 | 13.3 | 8 | 350.0 | 245 | 3.73 | 3.840 | 15.41 | 0 | 0 | 3 | 4 |
| Pontiac Firebird | 19.2 | 8 | 400.0 | 175 | 3.08 | 3.845 | 17.05 | 0 | 0 | 3 | 2 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Porsche 914-2 | 26.0 | 4 | 120.3 | 91 | 4.43 | 2.140 | 16.70 | 0 | 1 | 5 | 2 |
| Lotus Europa | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.90 | 1 | 1 | 5 | 2 |
| Ford Pantera L | 15.8 | 8 | 351.0 | 264 | 4.22 | 3.170 | 14.50 | 0 | 1 | 5 | 4 |
| Ferrari Dino | 19.7 | 6 | 145.0 | 175 | 3.62 | 2.770 | 15.50 | 0 | 1 | 5 | 6 |
| Maserati Bora | 15.0 | 8 | 301.0 | 335 | 3.54 | 3.570 | 14.60 | 0 | 1 | 5 | 8 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
Operador pipe %>%
Si bien no es necesario que utilice el operador de pipe con dplyr o tidyr, puede ser muy útil cuando intente realizar múltiples operaciones / funciones en un conjunto de datos. El operador pipe le permitirá evitar una operación larga anidada o hacer un montón de asignaciones. En su forma más básica.
# los Datos
df <- mtcars
Usando Nesting
library(dplyr)
arrange(sample_n(filter(df,mpg>20),size=5),desc(mpg))
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| Toyota Corolla | 33.9 | 4 | 71.1 | 65 | 4.22 | 1.835 | 19.90 | 1 | 1 | 4 | 1 |
| Fiat 128 | 32.4 | 4 | 78.7 | 66 | 4.08 | 2.200 | 19.47 | 1 | 1 | 4 | 1 |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
Usando Multiples asignaciones
library(dplyr)
a <- filter(df,mpg > 20) # selecciona un subconjunto del dataframe
b <- sample_n(a,size = 5) # toma una muestra aleatoria
c <- arrange(b,desc(mpg)) #orgniza el dataframe
c
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| Lotus Europa | 30.4 | 4 | 95.1 | 113 | 3.77 | 1.513 | 16.90 | 1 | 1 | 5 | 2 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Toyota Corona | 21.5 | 4 | 120.1 | 97 | 3.70 | 2.465 | 20.01 | 1 | 0 | 3 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
Usando el Operador pipe %>%
library(dplyr)
df %>% filter(mpg > 20) %>% sample_n(size = 5) %>% arrange(desc(mpg))
| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| Honda Civic | 30.4 | 4 | 75.7 | 52 | 4.93 | 1.615 | 18.52 | 1 | 1 | 4 | 2 |
| Fiat X1-9 | 27.3 | 4 | 79.0 | 66 | 4.08 | 1.935 | 18.90 | 1 | 1 | 4 | 1 |
| Merc 240D | 24.4 | 4 | 146.7 | 62 | 3.69 | 3.190 | 20.00 | 1 | 0 | 4 | 2 |
| Volvo 142E | 21.4 | 4 | 121.0 | 109 | 4.11 | 2.780 | 18.60 | 1 | 1 | 4 | 2 |
| Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |