Por Jose R. Zapata
Ultima actualizacion: 14/Nov/2023
SEABORN: Libreria de visualización de datos estadísticos de Python
Seaborn complementa a Matplotlib y se dirige específicamente a la visualización de datos estadísticos, funciona muy bien con pandas.
Instalacion Seaborn
se instala con el siguiente comando:
pip install seaborn.
Importar seaborn
Se importa de forma estandar de la siguiente manera:
import seaborn as sns
#para graficar dentro del jupyter notebook
%matplotlib inline
Datos integrados en seaborn
Seaborn viene con algunos data sets integrados, la lista competa se puede encontrar en: https://github.com/mwaskom/seaborn-data
tips = sns.load_dataset('tips') # Importar el dataset tips
type(tips)
pandas.core.frame.DataFrame
tips.head() # ver los primeros 5 registros
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
tips.dtypes #tipos de datos en el dataframe
total_bill float64
tip float64
sex category
smoker category
day category
time category
size int64
dtype: object
tips.describe() #Resumen estadistico de los datos del data frame por columna
| total_bill | tip | size | |
|---|---|---|---|
| count | 244.000000 | 244.000000 | 244.000000 |
| mean | 19.785943 | 2.998279 | 2.569672 |
| std | 8.902412 | 1.383638 | 0.951100 |
| min | 3.070000 | 1.000000 | 1.000000 |
| 25% | 13.347500 | 2.000000 | 2.000000 |
| 50% | 17.795000 | 2.900000 | 2.000000 |
| 75% | 24.127500 | 3.562500 | 3.000000 |
| max | 50.810000 | 10.000000 | 6.000000 |
Plots de Distribucion en Seaborn
distplot
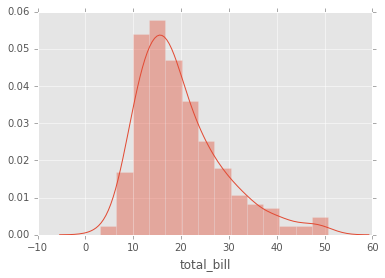
El distplot muestra la distribución de un conjunto univariante de observaciones.
sns.distplot(tips['total_bill']);
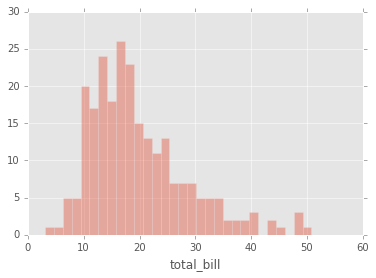
Si se quiere eliminar la grafica kde y solo tener el histograma entonces:
sns.distplot(tips['total_bill'],kde=False,bins=30);
jointplot
jointplot() le permite básicamente emparejar dos distplots para datos bivariados. Con su elección de que parámetro kind va comparar:
- “scatter”
- “reg”
- “resid”
- “kde”
- “hex”
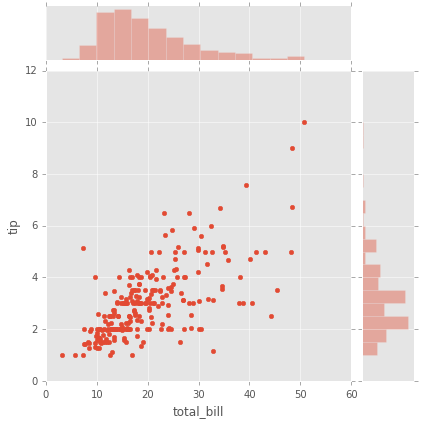
# Histogramas y scatter plot
sns.jointplot(x='total_bill',y='tip',data=tips,kind='scatter');
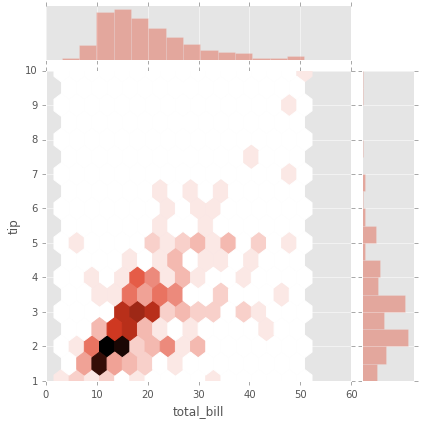
# Histogramas y hexagonal
sns.jointplot(x='total_bill',y='tip',data=tips,kind='hex');
#Hystogramas con kde y scatter plot
sns.jointplot(x='total_bill',y='tip',data=tips,kind='reg');
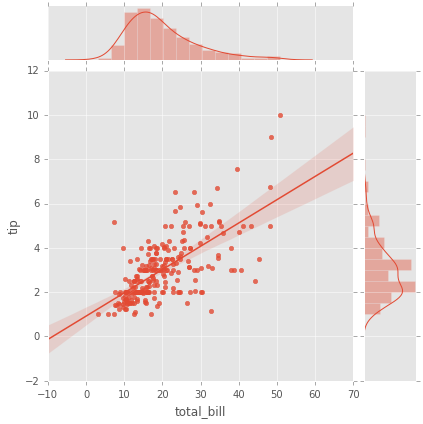
pairplot
pairplot grafica relaciones por pares en un dataframe completo (para las columnas numéricas) y soporta un argumento de tono de color(Hue) (para columnas categóricas).
#diagonal histogramas los demas son scatter plots
sns.pairplot(tips); # datos Numéricos
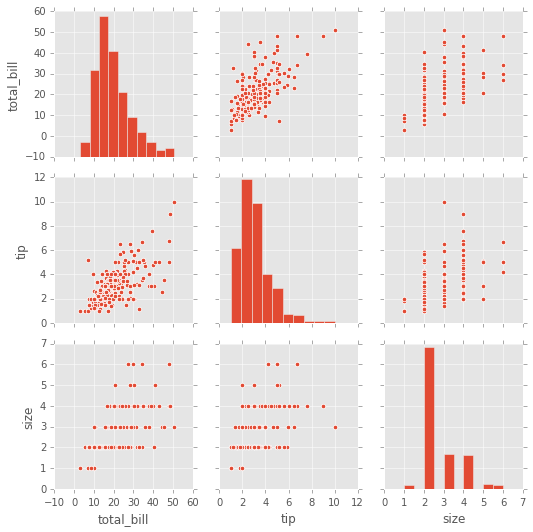
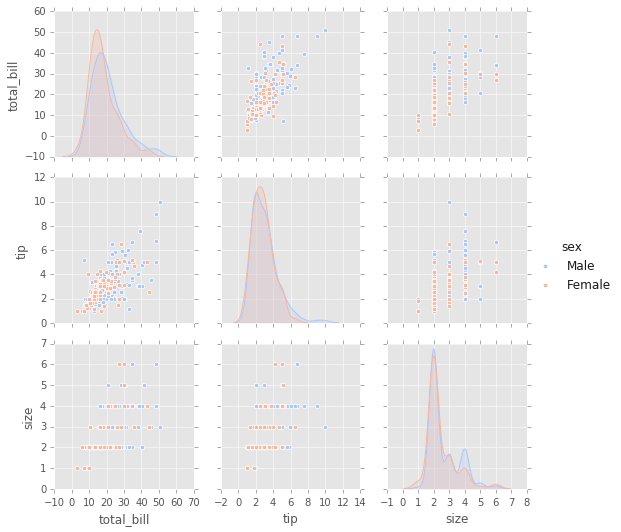
# Datos categoricos
# Diagonal KDE y los otros plots son scatter
sns.pairplot(tips,hue='sex',palette='coolwarm'); # cambio de colormap
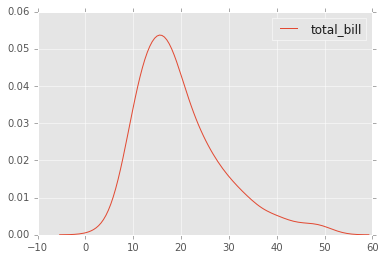
kdeplot
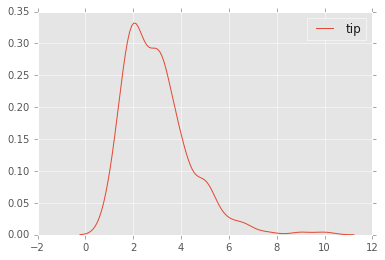
kdeplots son Gráficos de Estimación de Densidad del Núcleo.
# Variable 'total bill'
sns.kdeplot(tips['total_bill']) #plot kde
<matplotlib.axes._subplots.AxesSubplot at 0x7f47c6f3c860>
#Variable 'tip'
sns.kdeplot(tips['tip'])
<matplotlib.axes._subplots.AxesSubplot at 0x7f47c6964908>
Plots para datos categoricos
- boxplot
- violinplot
- stripplot
- swarmplot
- barplot
- countplot
import seaborn as sns
%matplotlib inline
barplot
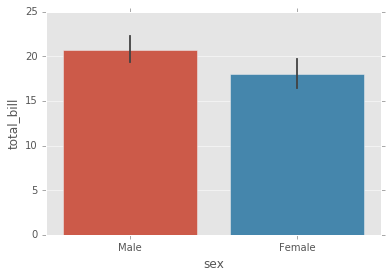
Es un gráfico general que le permite agregar los datos categóricos basados en alguna función, el valor predeterminado es la media:
sns.barplot(x='sex',y='total_bill',data=tips);
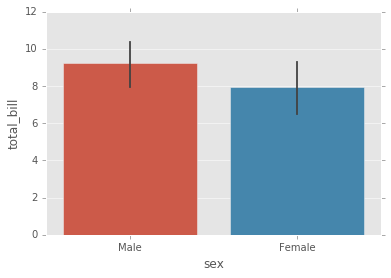
Puede cambiar el objeto estimador a su propia función, que convierte un vector a escalar:
import numpy as np
sns.barplot(x='sex',y='total_bill',data=tips,estimator=np.std); # la desviacion estandar como estimador
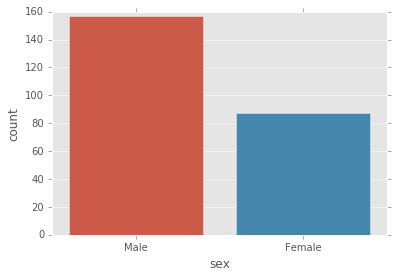
countplot
Esto es esencialmente lo mismo que Barplot, excepto que el estimador está contando explícitamente el número de ocurrencias. Por eso solo pasamos el valor de x:
sns.countplot(x='sex',data=tips);
boxplot
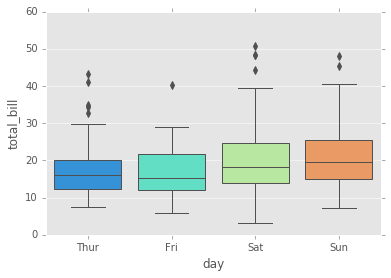
los boxplots (diagrama de caja) y violin plots se utilizan para mostrar la distribución de datos categóricos. Un diagrama de caja (boxplots o gráfico de caja y bigotes) muestra la distribución de datos cuantitativos de una manera que facilita las comparaciones entre variables o entre niveles de una variable categórica. El cuadro muestra los cuartiles del conjunto de datos, mientras que los bigotes se extienden para mostrar el resto de la distribución, a excepción de los puntos que se determinan como “valores atípicos” utilizando un método que es una función del rango intercuartílico.
sns.boxplot(x="day", y="total_bill", data=tips,palette='rainbow');
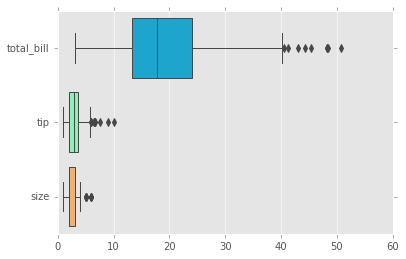
# se pueden graficar de forma horizontal
sns.boxplot(data=tips,palette='rainbow',orient='h');
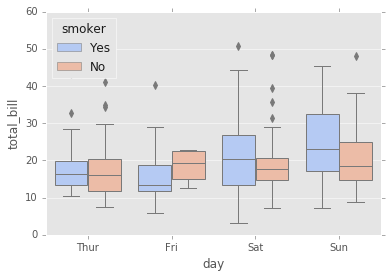
# cambiar el color y ver varias variables (hue)
sns.boxplot(x="day", y="total_bill", hue="smoker",data=tips, palette="coolwarm");
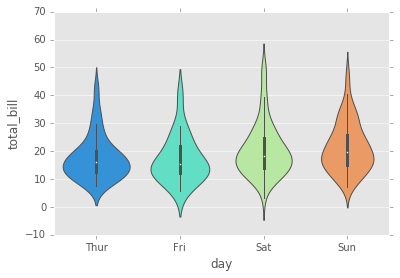
violinplot
Un plot de violín juega un papel similar a un box and whisker plot (diagrama de cajas y bigotes). Muestra la distribución de datos cuantitativos a través de varios niveles de una (o más) variables categóricas de modo que esas distribuciones se puedan comparar. A diferencia de un diagrama de caja, en el que todos los componentes de la gráfica corresponden a los puntos de datos reales, la gráfica del violín presenta una estimación de la densidad del núcleo de la distribución subyacente.
sns.violinplot(x="day", y="total_bill", data=tips,palette='rainbow');
# Varias Variables
sns.violinplot(x="day", y="total_bill", data=tips,hue='sex',palette='Set1');
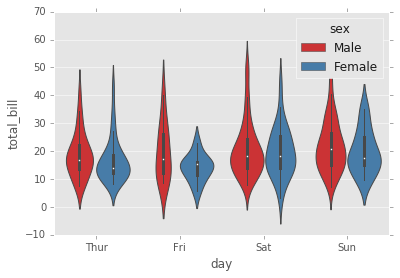
# Varias variables
sns.violinplot(x="day", y="total_bill", data=tips,hue='sex',split=True,palette='Set1');
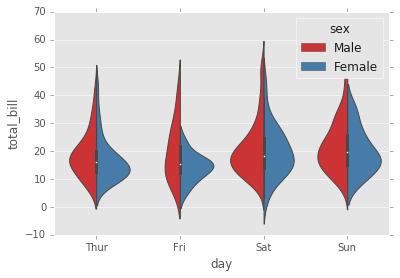
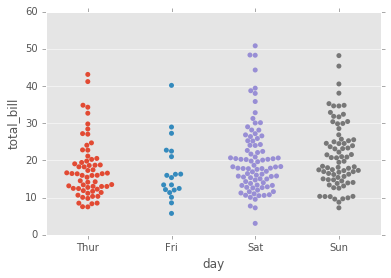
stripplot
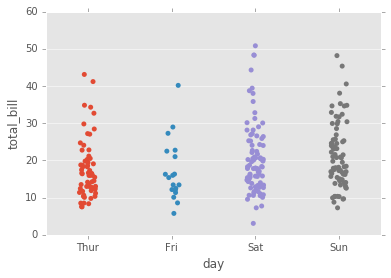
El stripplot dibujará un diagrama de dispersión donde una variable es categórica. Un stripplot se puede dibujar por sí mismo, pero también es un buen complemento de una casilla o trama de violín en los casos en que desea mostrar todas las observaciones junto con alguna representación de la distribución subyacente.
sns.stripplot(x="day", y="total_bill", data=tips);
sns.stripplot(x="day", y="total_bill", data=tips,jitter=True);
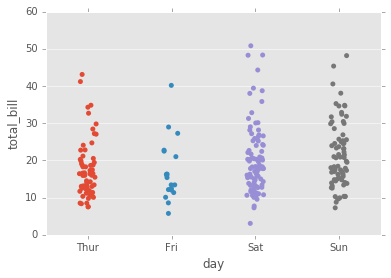
# Varias variables
sns.stripplot(x="day", y="total_bill", data=tips,jitter=True,hue='sex',palette='Set1');
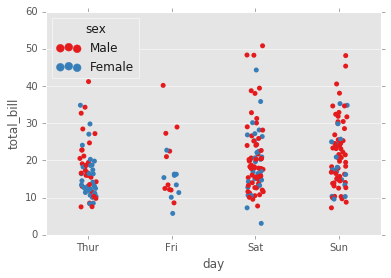
# Varias Variables
sns.stripplot(x="day", y="total_bill", data=tips,jitter=True,hue='sex',palette='Set1',dodge=True);
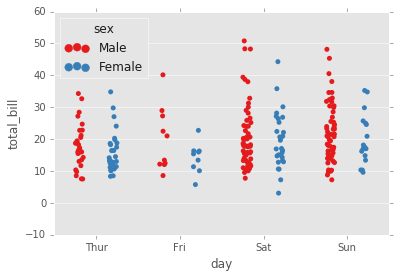
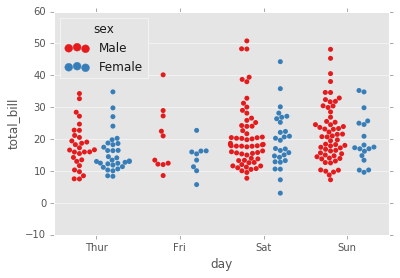
swarmplot
El swarmplot es similar a stripplot(), pero los puntos se ajustan (solo a lo largo del eje categórico) para que no se superpongan. Esto proporciona una mejor representación de la distribución de los valores, aunque no se ajusta a un gran número de observaciones (tanto en términos de la capacidad de mostrar todos los puntos como en términos del cálculo necesario para organizarlos).
sns.swarmplot(x="day", y="total_bill", data=tips);
sns.swarmplot(x="day", y="total_bill",hue='sex',data=tips, palette="Set1", dodge=True);
Combininando Plots Categoricos
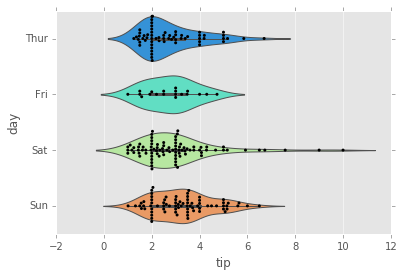
sns.violinplot(x="tip", y="day", data=tips,palette='rainbow')
sns.swarmplot(x="tip", y="day", data=tips,color='black',size=3);
Graficas de Matrices
Los Plot de matriz permiten graficar los datos como matrices codificadas por colores y también se pueden usar para indicar clústeres dentro de los datos, algunos de los mas usados son el heatmap y el clustermap de seaborn:
flights = sns.load_dataset('flights') # carga de datos
tips = sns.load_dataset('tips') # carga de datos
tips.head() # ver los primeros 5 elementos de la tabla
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
flights.head() # ver los primeros 5 elementos de la tabla
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | January | 112 |
| 1 | 1949 | February | 118 |
| 2 | 1949 | March | 132 |
| 3 | 1949 | April | 129 |
| 4 | 1949 | May | 121 |
Heatmap
Para que un mapa de calor funcióne correctamente, los datos ya deben estar en forma de matriz, la función de sns.heatmap básicamente los colorea. Por ejemplo:
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
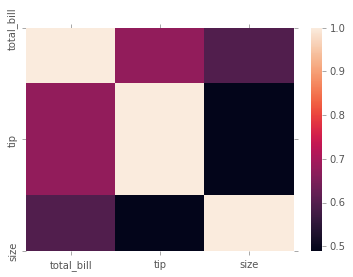
# Matriz de correlacion de los datos
tips.corr()
| total_bill | tip | size | |
|---|---|---|---|
| total_bill | 1.000000 | 0.675734 | 0.598315 |
| tip | 0.675734 | 1.000000 | 0.489299 |
| size | 0.598315 | 0.489299 | 1.000000 |
# Heatmap de la matriz de correlacion
sns.heatmap(tips.corr());
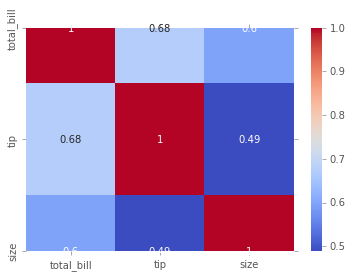
# Cambiando el mapa de colres y agregando las anotaciones a la grafica
sns.heatmap(tips.corr(),cmap='coolwarm',annot=True);
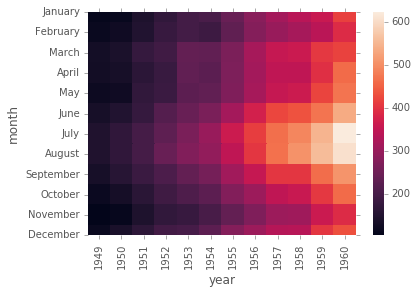
O para los datos de vuelos:
# Definir una pivot table
flights.pivot_table(values='passengers',index='month',columns='year')
| year | 1949 | 1950 | 1951 | 1952 | 1953 | 1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month | ||||||||||||
| January | 112 | 115 | 145 | 171 | 196 | 204 | 242 | 284 | 315 | 340 | 360 | 417 |
| February | 118 | 126 | 150 | 180 | 196 | 188 | 233 | 277 | 301 | 318 | 342 | 391 |
| March | 132 | 141 | 178 | 193 | 236 | 235 | 267 | 317 | 356 | 362 | 406 | 419 |
| April | 129 | 135 | 163 | 181 | 235 | 227 | 269 | 313 | 348 | 348 | 396 | 461 |
| May | 121 | 125 | 172 | 183 | 229 | 234 | 270 | 318 | 355 | 363 | 420 | 472 |
| June | 135 | 149 | 178 | 218 | 243 | 264 | 315 | 374 | 422 | 435 | 472 | 535 |
| July | 148 | 170 | 199 | 230 | 264 | 302 | 364 | 413 | 465 | 491 | 548 | 622 |
| August | 148 | 170 | 199 | 242 | 272 | 293 | 347 | 405 | 467 | 505 | 559 | 606 |
| September | 136 | 158 | 184 | 209 | 237 | 259 | 312 | 355 | 404 | 404 | 463 | 508 |
| October | 119 | 133 | 162 | 191 | 211 | 229 | 274 | 306 | 347 | 359 | 407 | 461 |
| November | 104 | 114 | 146 | 172 | 180 | 203 | 237 | 271 | 305 | 310 | 362 | 390 |
| December | 118 | 140 | 166 | 194 | 201 | 229 | 278 | 306 | 336 | 337 | 405 | 432 |
# Graficar la pivot table como un heatmap
pvflights = flights.pivot_table(values='passengers',index='month',columns='year')
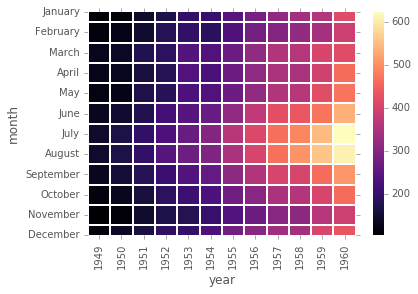
sns.heatmap(pvflights);
# Cambiando los parametros del colormap y el ancho y color de las lineas d division
sns.heatmap(pvflights,cmap='magma',linecolor='white',linewidths=1);
clustermap
El mapa de clúster utiliza la agrupación jerárquica para producir una versión agrupada del mapa de calor. Por ejemplo:
# Grafica Clustermap de la tabla pivot de los vuelos
sns.clustermap(pvflights);
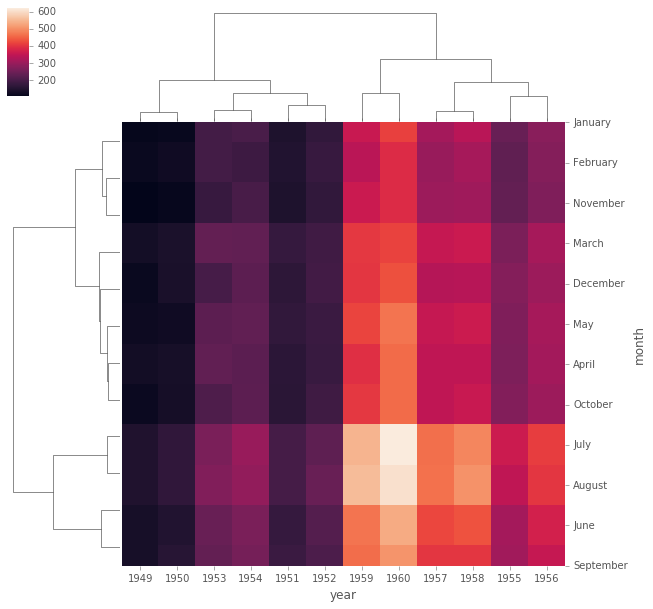
Observe ahora cómo los años y meses ya no están en orden, en su lugar se agrupan por similitud en el valor (recuento de pasajeros). Eso significa que podemos comenzar a inferir cosas de esta trama, como agosto y julio siendo similares (tiene sentido, ya que ambos son meses de viaje de verano)
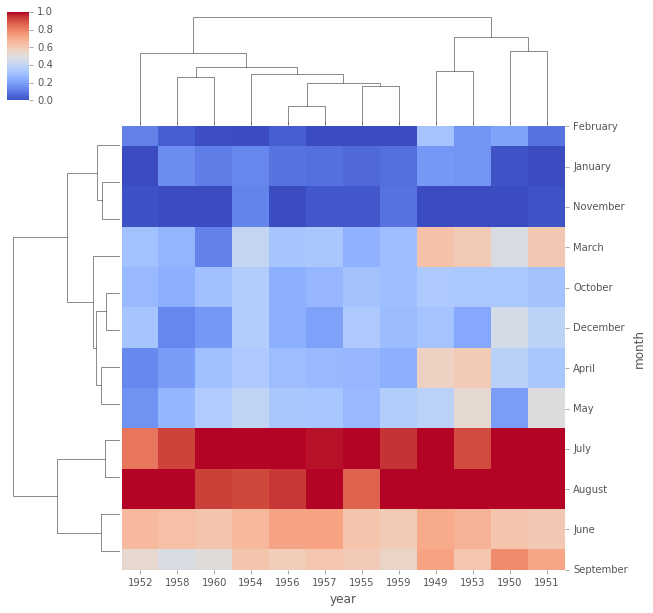
# Más opciones para obtener la información un poco más clara como la normalización
# Cambiar el colormap
sns.clustermap(pvflights,cmap='coolwarm',standard_scale=1);
Grids
Las grids son tipos generales de plots que le permiten mapear tipos de plots en filas y columnas de una cuadrícula, esto le ayuda a crear plots similares separadas por características.
# Importar librerias
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
iris = sns.load_dataset('iris') #Importar el dataset
iris.head() #Ver los primeros 5 elementos de la tabla
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
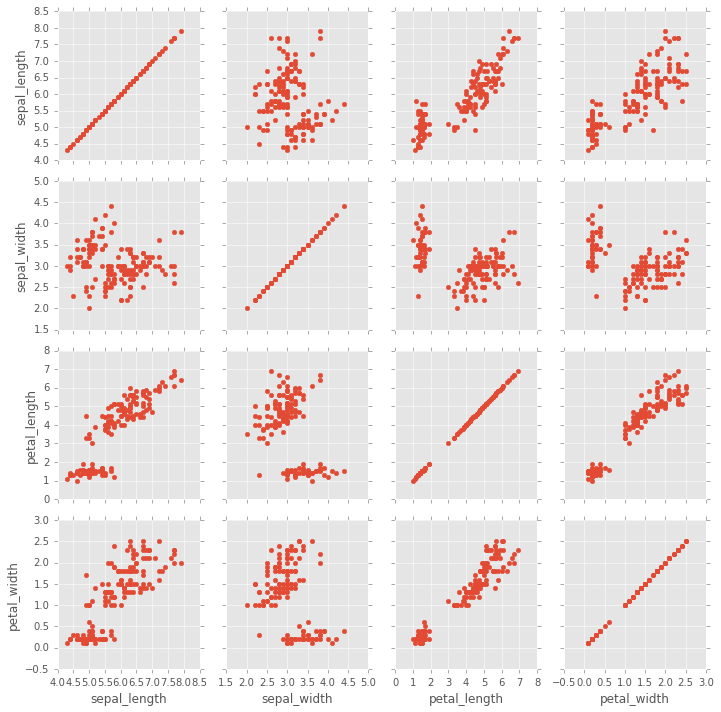
PairGrid
Pairgrid es un subplot grid para graficar relaciones por pares en un conjunto de datos.
# solo el Grid
sns.PairGrid(iris);

# Ahora se mapea el grid
g = sns.PairGrid(iris)
g.map(plt.scatter);
# Mapear a arriba, abajo y diagonal
g = sns.PairGrid(iris) # crear una cuadricula
g.map_diag(plt.hist) #Histogramas en la diagonal
g.map_upper(plt.scatter) # Scatter plots en la parte superior
g.map_lower(sns.kdeplot); # Plots de densidad kde en la parte inferior
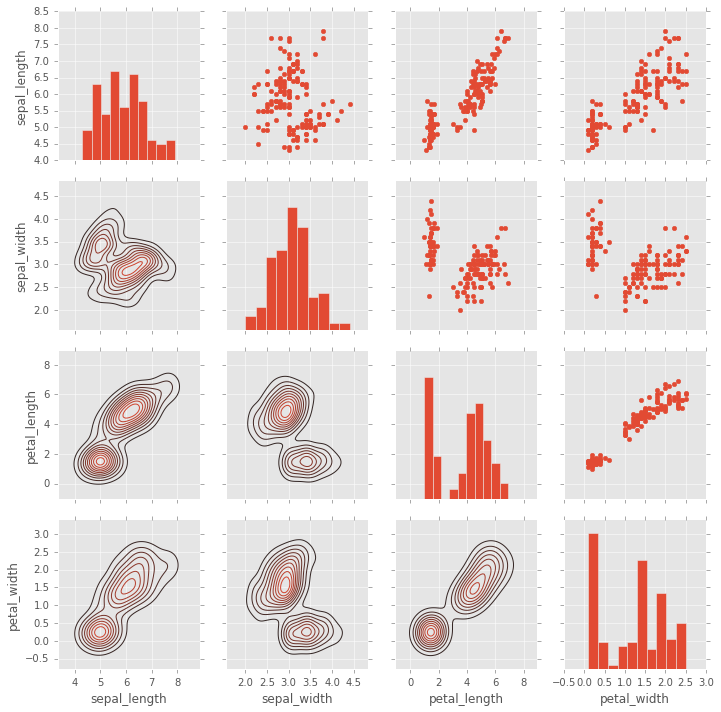
pairplot
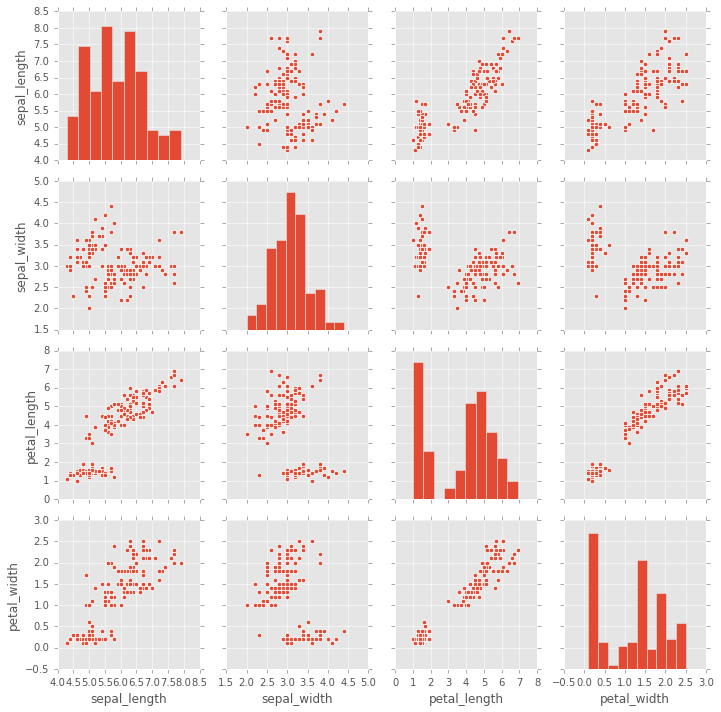
pairplot es una versión más simple de PairGrid (se usa con bastante frecuencia)
# La diagonal es un histograma
# las otras graficas son scatter plots
sns.pairplot(iris);
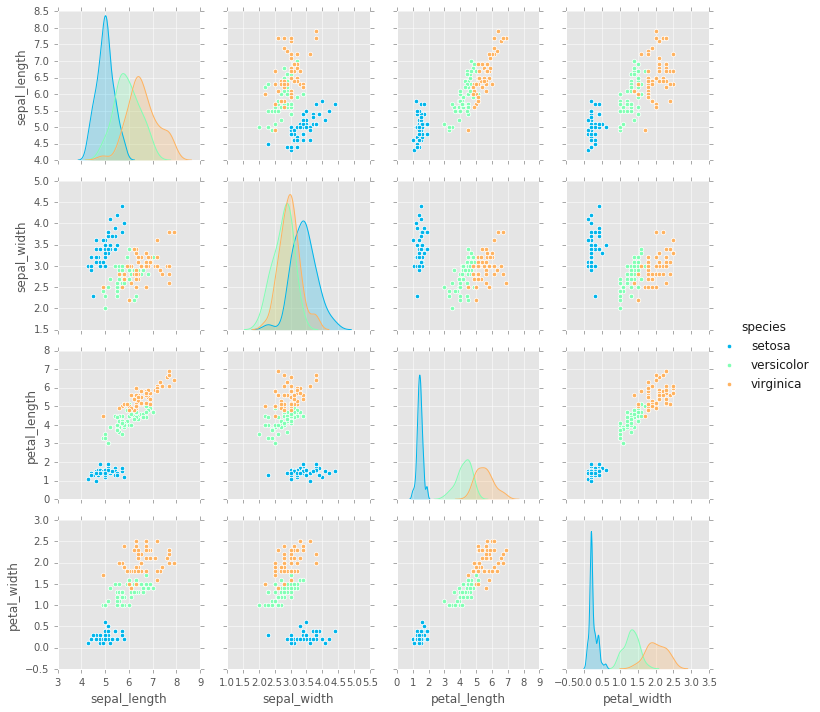
# la diagonal son kde de los datos categoricos
# las otars graficas son scatter plots
sns.pairplot(iris,hue='species',palette='rainbow');
Facet Grid
FacetGrid es la forma general de crear grids de plots basados en dos caracteristica:
tips = sns.load_dataset('tips')
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
# Solo el Grid
g = sns.FacetGrid(tips, col="time", row="smoker");
# histogramas entre las dos variables
g = sns.FacetGrid(tips, col="time", row="smoker")
g = g.map(plt.hist, "total_bill")
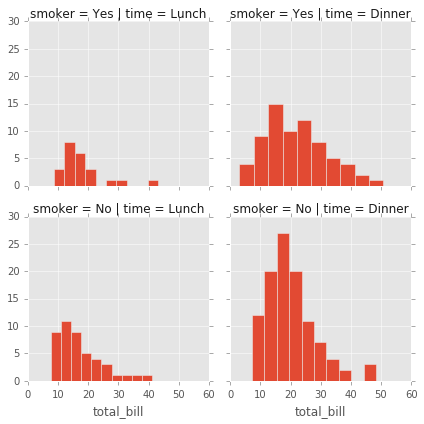
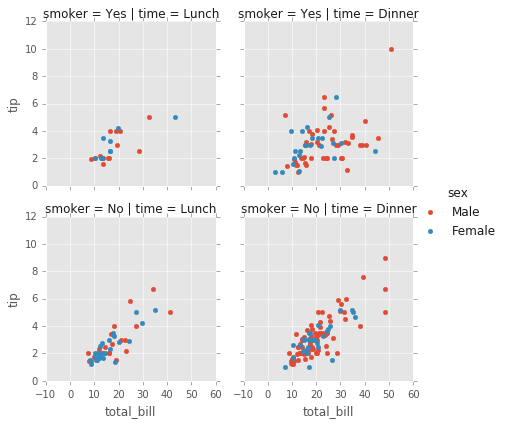
# Scatterplots
g = sns.FacetGrid(tips, col="time", row="smoker",hue='sex')
# Observe como los argumentos vienen despues de llamar a plt.scatter
g = g.map(plt.scatter, "total_bill", "tip").add_legend()
JointGrid
JointGrid es la version general de jointplot()
# Solo el grid
g = sns.JointGrid(x="total_bill", y="tip", data=tips)
# Grafica de regresion y histograma con kde
g = sns.JointGrid(x="total_bill", y="tip", data=tips)
g = g.plot(sns.regplot, sns.distplot)
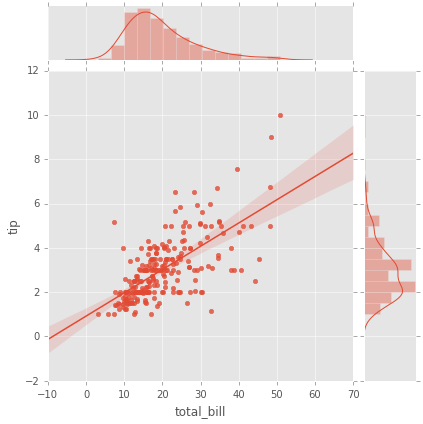
Plots de Regresion
Seaborn tiene muchas capacidades integradas para trazados de regresión, lmplot le permite visualizar modelos lineales, pero también le permite dividir los gráficos en función de las características, así como también colorear el tono (hue) en función de las características.
#Importar librerias
import seaborn as sns
%matplotlib inline
tips = sns.load_dataset('tips') # importar el dataset
tips.head() # ver los primeros datos del dataset
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
lmplot()
#scatter plot mas la regresion lineal
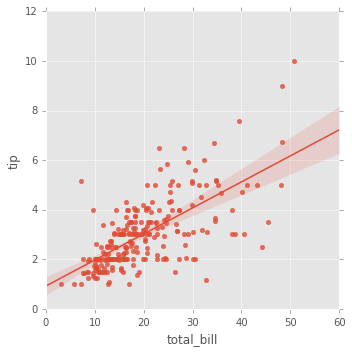
sns.lmplot(x='total_bill',y='tip',data=tips);
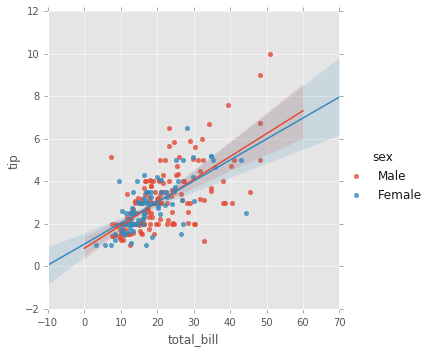
#scatter plot mas la regresion lineal basado en el genero
sns.lmplot(x='total_bill',y='tip',data=tips,hue='sex');
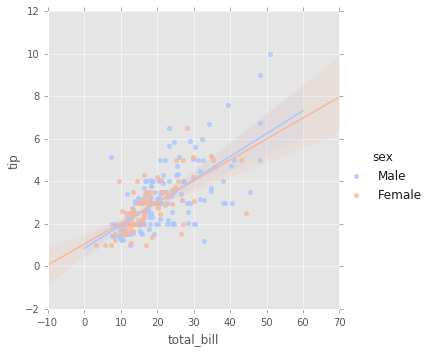
# Cambio de paleta de colores
sns.lmplot(x='total_bill',y='tip',data=tips,hue='sex',palette='coolwarm');
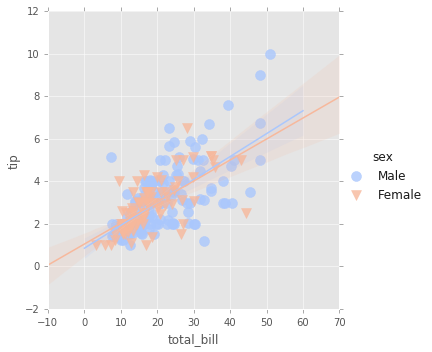
Usando Marcadores
Los argumentos kwargs lmplot pasan a regplto que es una forma más general de lmplot(). regplot tiene un parámetro scatter_kws que se pasa a plt.scatter y puede modificar los parametros.
Mire siempre la documentacion http://matplotlib.org/api/markers_api.html
# http://matplotlib.org/api/markers_api.html
sns.lmplot(x='total_bill',y='tip',data=tips,hue='sex',palette='coolwarm',
markers=['o','v'],scatter_kws={'s':100});
Usando un Grid
Podemos agregar una separación más variable a través de columnas y filas con el uso de un grid. Simplemente indícandolo en los argumentos col o row:
sns.lmplot(x='total_bill',y='tip',data=tips,col='sex'); #hace una division por el genero
# division por el genero y por tiempo de almuerzo o cena
sns.lmplot(x="total_bill", y="tip", row="sex", col="time",data=tips);
# información del genero en HUE
sns.lmplot(x='total_bill',y='tip',data=tips,col='day',hue='sex',palette='coolwarm');
Aspecto y Tamaño
Las figuras de Seaborn se les puede ajustar su tamaño y relación de aspecto con los parámetros height y aspect:
sns.lmplot(x='total_bill',y='tip',data=tips,col='day',hue='sex',palette='coolwarm',
aspect=0.6,height=8);
Referencias
- http://seaborn.pydata.org/ - Documentacion Seaborn otra libreria de graficas estadisticas
Phd. Jose R. Zapata