Ultima actualizacion: 2/Noviembre/2024 - Pandas 2.2.2
Pandas es una herramienta de manipulación de datos de alto nivel desarrollada por Wes McKinney. En su inicio es construido sobre Numpy y ahora compatible con Arrow y permite el análisis de datos que cuenta con las estructuras de datos que necesitamos para limpiar los datos en bruto y que sean aptos para el análisis (por ejemplo, tablas). Pandas permite realizar tareas importantes, como alinear datos para su comparación, fusionar conjuntos de datos, gestión de datos perdidos, etc., se ha convertido en una librería muy importante para procesar datos a alto nivel en Python (es decir, estadísticas ). Pandas fue diseñada originalmente para gestionar datos financieros, y como alternativo al uso de hojas de cálculo (es decir, Microsoft Excel).
Los principales tipos de datos que pueden representarse con pandas son:
Datos tabulares con columnas de tipo heterogéneo con etiquetas en columnas y filas.
Series temporales
Pandas proporciona herramientas que permiten:
leer y escribir datos en diferentes formatos: CSV, JSON, Excel, bases SQL, parquet y HDF5 entre otros
seleccionar y filtrar de manera sencilla tablas de datos en función de posición, valor o etiquetas
fusionar y unir datos
transformar datos aplicando funciones tanto en global como por ventanas
manipulación de series temporales
hacer gráficas
En pandas existen 2 tipos básicos de objetos todos ellos basados a su vez en Numpy y ahora en Arrow:
Series (listas, 1D)
DataFrame (tablas, 2D)
Por lo tanto, Pandas nos proporciona las estructuras de datos y funciones necesarias para el análisis de datos.
Instalar Pandas
Pandas ya esta preinstalado si se usa Google Collaboratory, si va realizar una instalacion en su computador
La libreria Pandas se importa de la siguiente manera
importnumpyasnp# Importación estándar de la librería NumPyimportpandasaspd# Importación estándar de la librería Pandas
pd.__version__
'2.2.2'
Series
Una serie es el primer tipo de datos de pandas y es muy similar a una matriz NumPy (de hecho está construida sobre el objeto de matriz NumPy). Lo que diferencia un arreglo NumPy de una serie, es que una serie puede tener etiquetas en los ejes, lo que significa que puede ser indexada por una etiqueta, en lugar de solo una ubicación numérica. Tampoco necesita contener datos numéricos, puede contener cualquier Objeto de Python arbitrario.
Creando una Serie
Puede convertir una lista, una matriz numpy o un diccionario en una serie, usando el método pd.Series:
# Crear diferentes tipos de datoslabels=["a","b","c"]# lista de etiquetasmy_list=[10,20,30]# lista con valoresarr=np.array([10,20,30])# Convertir lista de valores en arreglo NumPyd={"a":10,"b":20,"c":30}# Creación de un diccionario
Desde Listas
# Convertir una lista en series usando el método pd.Series# observe que se crean los nombres con las posiciones de cada elementopd.Series(data=my_list)
0 10
1 20
2 30
dtype: int64
# Convertir una lista en series usando el método pd.Series# se puede ingresar el nombre de las posicionespd.Series(data=my_list,index=labels)
a 10
b 20
c 30
dtype: int64
# No es necesario ingresar la palabra de 'data ='' en el argumentopd.Series(my_list,labels)
a 10
b 20
c 30
dtype: int64
Desde Arreglos NumPy
# Convertir un arreglo en series usando el método pd.Seriespd.Series(arr)
0 10
1 20
2 30
dtype: int64
# Convertir un arreglo en series indicando también los valores del indexpd.Series(arr,labels)
a 10
b 20
c 30
dtype: int64
Desde un Diccionario
# Convertir un diccionario en series usando el método pd.Series# Como el diccionario ya tiene clave entonces se le asigna como valor de la posiciónpd.Series(d)
a 10
b 20
c 30
dtype: int64
Datos en una Series
Una serie de pandas puede contener una variedad de tipos de objetos:
# Creando una serie basado solo en una lista de letraspd.Series(data=labels)
0 a
1 b
2 c
dtype: object
Indexacion
La clave para usar una serie es entender su índice. Pandas hace uso de estos nombres o números de índice al permitir búsquedas rápidas de información (funciona como una tabla hash o diccionario).
Veamos algunos ejemplos de cómo obtener información de una serie. Vamos a crear dos series, ser1 y ser2:
# Creación de una serie con sus labels o indicesser1=pd.Series([1,2,3,4],index=["USA","Alemania","Italia","Japon"])
ser1
USA 1
Alemania 2
Italia 3
Japon 4
dtype: int64
# Creación de una serie con sus labels o indicesser2=pd.Series([1,2,5,4],index=["USA","Alemania","Colombia","Japon"])
ser2
USA 1
Alemania 2
Colombia 5
Japon 4
dtype: int64
# La búsqueda en una serie es igual como en un diccionarioser1["USA"]
1
# La búsqueda en una serie es igual como en un diccionarioser2["Colombia"]
5
Las operaciones también se realizan según el índice:
# Observe los resultados de los países que solo están en una serie y no en las dosser1+ser2
Alemania 4.0
Colombia NaN
Italia NaN
Japon 8.0
USA 2.0
dtype: float64
DataFrames
Los DataFrames son la estructura mas importante en pandas y están directamente inspirados en el lenguaje de programación R. Se puede pensar en un DataFrame como un conjunto de Series reunidas que comparten el mismo índice.
En los DataFrame tenemos la opción de especificar tanto el index (el nombre de las filas) como columns (el nombre de las columnas).
# Importar la función de NumPy para crear arreglos de números enterosfromnumpy.randomimportrandnnp.random.seed(101)# Inicializar el generador aleatorio
# Forma rápida de crear una lista de python desde strings"A B C D E F".split()
['A', 'B', 'C', 'D', 'E', 'F']
# Crear un dataframe con números aleatorios de 4 Columnas y 5 Filas# Crear listas rápidamente usando la función split 'A B C D E'.split()# Esto evita tener que escribir repetidamente las comasdf=pd.DataFrame(randn(6,4),index="A B C D E F".split(),columns="W X Y Z".split())
df
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
Descripcion general del dataframe
Numero de Filas y Columnas
df.shape# retorna un Tuple asi: (filas, col)
(6, 4)
información General de los datos
# información general de los datos de cada columna# Indica el numero de filas del dataset# Muestra el numero de datos No Nulos por columna (valores validos)# Tipo de dato de cada columna# Tamaño total del datasetdf.info()
<class 'pandas.core.frame.DataFrame'>
Index: 6 entries, A to F
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 W 6 non-null float64
1 X 6 non-null float64
2 Y 6 non-null float64
3 Z 6 non-null float64
dtypes: float64(4)
memory usage: 240.0+ bytes
# Tipos de datos que existen en las columnas del dataframedf.dtypes
W float64
X float64
Y float64
Z float64
dtype: object
Resumen de estadistica descriptiva General
el método .describe() de los dataframes presenta un resumen de la estadistica descriptiva general de las columnas numericas del dataframe, presenta la información de:
Promedio (mean)
Desviacion estandard (std)
Valor minimo
Valor maximo
Cuartiles (25%, 50% y 75%)
df.describe()# No muestra la información de las columnas categóricas
W
X
Y
Z
count
6.000000
6.000000
6.000000
6.000000
mean
0.336992
0.660424
0.092558
0.166706
std
1.503744
1.075862
1.571280
0.839534
min
-2.018168
-0.758872
-1.706086
-1.159119
25%
0.189220
-0.082455
-0.911947
-0.315794
50%
0.246730
0.684127
-0.159632
0.554896
75%
0.564005
1.455323
0.813180
0.664123
max
2.706850
1.978757
2.605967
0.955057
Ver Primeros elementos del dataframe
df.head()
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
Ver Ultimos elementos del dataframe
df.tail()
W
X
Y
Z
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
Ver elementos aleatorios del dataframe
df.sample(3)
W
X
Y
Z
B
0.651118
-0.319318
-0.848077
0.605965
D
0.188695
-0.758872
-0.933237
0.955057
C
-2.018168
0.740122
0.528813
-0.589001
Seleccion y Indexacion
Existen diversos métodos para tomar datos de un DataFrame
# Regresara todos los datos de la columna Wdf["W"]
A 2.706850
B 0.651118
C -2.018168
D 0.188695
E 0.190794
F 0.302665
Name: W, dtype: float64
# Seleccionar dos o mas columnas# Pasar una lista con los nombres de las columnasdf[["W","Z"]]
W
Z
A
2.706850
0.503826
B
0.651118
0.605965
C
-2.018168
-0.589001
D
0.188695
0.955057
E
0.190794
0.683509
F
0.302665
-1.159119
# Seleccionar dos o mas columnas# Pasar una lista con los nombres de las columnas# Puedo indicar el orden de las columnasdf[["X","W","Z"]]
X
W
Z
A
0.628133
2.706850
0.503826
B
-0.319318
0.651118
0.605965
C
0.740122
-2.018168
-0.589001
D
-0.758872
0.188695
0.955057
E
1.978757
0.190794
0.683509
F
1.693723
0.302665
-1.159119
Las columnas de un DataFrame Columns son solo Series
type(df["W"])# Tipos de datos
pandas.core.series.Series
Creando una Nueva Columna
# Nueva columna igual a la suma de otras dos# operación vectorialdf["new"]=df["W"]+df["Y"]df
W
X
Y
Z
new
A
2.706850
0.628133
0.907969
0.503826
3.614819
B
0.651118
-0.319318
-0.848077
0.605965
-0.196959
C
-2.018168
0.740122
0.528813
-0.589001
-1.489355
D
0.188695
-0.758872
-0.933237
0.955057
-0.744542
E
0.190794
1.978757
2.605967
0.683509
2.796762
F
0.302665
1.693723
-1.706086
-1.159119
-1.403420
Eliminando Columnas
df.drop("new",axis="columns")
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
# No se aplica a el dataframe a menos que se especifique.# Como se ve la operación pasada no quedo grabadadf
W
X
Y
Z
new
A
2.706850
0.628133
0.907969
0.503826
3.614819
B
0.651118
-0.319318
-0.848077
0.605965
-0.196959
C
-2.018168
0.740122
0.528813
-0.589001
-1.489355
D
0.188695
-0.758872
-0.933237
0.955057
-0.744542
E
0.190794
1.978757
2.605967
0.683509
2.796762
F
0.302665
1.693723
-1.706086
-1.159119
-1.403420
# Para que quede grabado se puede hacer de dos formas# df = df.drop('new',axis='columns') # Forma 1df.drop("new",axis="columns",inplace=True)# Forma 2df
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
df
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
También se puede sacar filas de esta manera:
df.drop("E",axis="index")
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
F
0.302665
1.693723
-1.706086
-1.159119
df
W
X
Y
Z
A
2.706850
0.628133
0.907969
0.503826
B
0.651118
-0.319318
-0.848077
0.605965
C
-2.018168
0.740122
0.528813
-0.589001
D
0.188695
-0.758872
-0.933237
0.955057
E
0.190794
1.978757
2.605967
0.683509
F
0.302665
1.693723
-1.706086
-1.159119
# Otra manera de borrar las columnas esdeldf["X"]# Esta función es INPLACEdf
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
C
-2.018168
0.528813
-0.589001
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
Obtener los nombres de las columnas y los indices (index):
DataFrame.loc[etiqueta_fila, etiqueta_columna] <- por etiquetas
DataFrame.iloc[indice_fila, indice_columna] <- por indices
# la función loc busca por medio de los nombres de los indices y columnasdf.loc["A"]# se selecciona todos los valores de la fila 'A'
W 2.706850
Y 0.907969
Z 0.503826
Name: A, dtype: float64
O basado en la posición (index) en vez de usar la etiqueta
df.iloc[2]# Se seleccionan los valores de la fila con indice 2# recordar que los index empiezan en cero
W -2.018168
Y 0.528813
Z -0.589001
Name: C, dtype: float64
Seleccionar un subconjunto de filas y columnas
# Mediante etiquetas# se selecciona el elemento que esta en la fila=B Col=Ydf.loc["B","Y"]# con etiquetas
-0.8480769834036315
# Mediante etiquetas# se selecciona un subconjunto de datos que están entre# filas = A, B Cols= W, Ydf.loc[["A","B"],["W","Y"]]
W
Y
A
2.706850
0.907969
B
0.651118
-0.848077
df.loc[["B","A"],["Y","W"]]
Y
W
B
-0.848077
0.651118
A
0.907969
2.706850
Seleccion Condicional o Filtros
Una característica importante de pandas es la selección condicional usando la notación de corchetes, muy similar a NumPy:
df
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
C
-2.018168
0.528813
-0.589001
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
# Devuelve una serie con booleans# según si se cumple o no la condicióndf["W"]>0
A True
B True
C False
D True
E True
F True
Name: W, dtype: bool
# seleccionar todas las filas del dataframe donde el valor# que esta en la columna 'W' sea mayor que cerodf[df["W"]>0]
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
# Seleccionar las filas donde 'W' sea mayor que cero# y de esas filas escoger los valores de la columna 'Y'df[df["W"]>0]["Y"]
A 0.907969
B -0.848077
D -0.933237
E 2.605967
F -1.706086
Name: Y, dtype: float64
# Seleccionar las filas donde 'W' sea mayor que cero# y de esas filas escoger los valores de las columna 'Y' y 'X'df[df["W"]>0][["Y","Z"]]
Y
Z
A
0.907969
0.503826
B
-0.848077
0.605965
D
-0.933237
0.955057
E
2.605967
0.683509
F
-1.706086
-1.159119
Para dos condiciones, se usa los booleanos de esta forma
| en vez de or
& en vez de and
~ en vez de not
Por amor a Dios, recuerde usar paréntesis:
# Seleccionar las filas donde 'W' sea mayor que cero# y también donde 'Y' sea mayor que 0.5limite_x=0limite_y=0.5df[(df["W"]>limite_x)&(df["Y"]>limite_y)]
W
Y
Z
A
2.706850
0.907969
0.503826
E
0.190794
2.605967
0.683509
.query() Busqueda condicional
Los terminos de busqueda condicional o filtros se entregan al método como tipo ‘string’
df
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
C
-2.018168
0.528813
-0.589001
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
# seleccionar todas las filas donde el valor# que esta en la columna 'W' sea mayor que cero# df[df['W']>0]df.query("W>0")
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
# Seleccionar las filas donde 'W' sea mayor que cero# y de esas filas escoger los valores de la columna 'Y'# df[df['W']>0]['Y']df.query("W>0")["Y"]
A 0.907969
B -0.848077
D -0.933237
E 2.605967
F -1.706086
Name: Y, dtype: float64
# Seleccionar las filas donde 'W' sea mayor que cero# y de esas filas escoger los valores de las columna 'Y' y 'X'# df[df['W']>0][['Y','Z']]df.query("W>0")[["Y","Z"]]
Y
Z
A
0.907969
0.503826
B
-0.848077
0.605965
D
-0.933237
0.955057
E
2.605967
0.683509
F
-1.706086
-1.159119
Para dos condiciones, puede usar | = or y & = and con paréntesis:
# Seleccionar las filas donde 'W' sea mayor que cero# y también donde 'Y' sea mayor que 0.5# df[(df['W']>0) & (df['Y'] > 0.5)]df.query("W>0 and Y>0.5")
W
Y
Z
A
2.706850
0.907969
0.503826
E
0.190794
2.605967
0.683509
Cambio de columna de Indexacion
Analicemos algunas características más de la indexación, incluido el restablecimiento del índice o el establecimiento de parámetros.
df
W
Y
Z
A
2.706850
0.907969
0.503826
B
0.651118
-0.848077
0.605965
C
-2.018168
0.528813
-0.589001
D
0.188695
-0.933237
0.955057
E
0.190794
2.605967
0.683509
F
0.302665
-1.706086
-1.159119
Se puede reiniciar el indice con numeros consecutivos
df.reset_index()# reset el indice# el index anterior se convierte en una columna
index
W
Y
Z
0
A
2.706850
0.907969
0.503826
1
B
0.651118
-0.848077
0.605965
2
C
-2.018168
0.528813
-0.589001
3
D
0.188695
-0.933237
0.955057
4
E
0.190794
2.605967
0.683509
5
F
0.302665
-1.706086
-1.159119
Se puede Redefinir el indice con los valores de otra columna
# Es importante tener valores que no sean duplicadosdf["States"]=["CA","NY","WY","OR","CO","FL"]df
W
Y
Z
States
A
2.706850
0.907969
0.503826
CA
B
0.651118
-0.848077
0.605965
NY
C
-2.018168
0.528813
-0.589001
WY
D
0.188695
-0.933237
0.955057
OR
E
0.190794
2.605967
0.683509
CO
F
0.302665
-1.706086
-1.159119
FL
# Redefinir la columna states como el indicedf=df.set_index("States",drop=True)df
W
Y
Z
States
CA
2.706850
0.907969
0.503826
NY
0.651118
-0.848077
0.605965
WY
-2.018168
0.528813
-0.589001
OR
0.188695
-0.933237
0.955057
CO
0.190794
2.605967
0.683509
FL
0.302665
-1.706086
-1.159119
Groupby (Agrupacion por filas)
El método groupby le permite agrupar filas de datos y llamar a funciones agregadas
# Crear dataframe desde un diccionariodata={"Company":["GOOG","GOOG","MSFT","MSFT","FB","FB","GOOG","MSFT","FB"],"Person":["Sam","Charlie","Amy","Vanessa","Carl","Sarah","John","Randy","David",],"Sales":[200,120,340,124,243,350,275,400,180],}# conversion del diccionario a dataframedf=pd.DataFrame(data)df
Company
Person
Sales
0
GOOG
Sam
200
1
GOOG
Charlie
120
2
MSFT
Amy
340
3
MSFT
Vanessa
124
4
FB
Carl
243
5
FB
Sarah
350
6
GOOG
John
275
7
MSFT
Randy
400
8
FB
David
180
Se puede usar el método .groupby() para agrupar filas en función de un nombre de columna. Por ejemplo, vamos a agruparnos a partir de la Compañía. Esto creará un objeto DataFrameGroupBy:
# agrupar por Companydf.groupby("Company")
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x724ca5feb6d0>
utilizar los métodos agregados del objeto:
# agrupar por compañía y calcular el promedio por cada unadf.groupby("Company").mean(numeric_only=True)
Sales
Company
FB
257.666667
GOOG
198.333333
MSFT
288.000000
Más ejemplos de métodos agregados:
# agrupar por compañía y calcular la desviación estándardf.groupby("Company").std(numeric_only=True)
Sales
Company
FB
85.943780
GOOG
77.513440
MSFT
145.161978
# agrupar por compañía y calcular el mínimodf.groupby("Company").min()
Person
Sales
Company
FB
Carl
180
GOOG
Charlie
120
MSFT
Amy
124
# agrupar por compañía y calcular el máximodf.groupby("Company").max()
Person
Sales
Company
FB
Sarah
350
GOOG
Sam
275
MSFT
Vanessa
400
# agrupar por compañía y sumar los elementos que hay excluyendo los NaNdf.groupby("Company").count()
Person
Sales
Company
FB
3
3
GOOG
3
3
MSFT
3
3
# Una de las funciones mas usadas para descripción estadística de un dataframe# Genera estadísticas descriptivas que resumen la tendencia central,# la dispersión y la forma de la distribución de un conjunto de datos,# excluyendo los valores `` NaN``.# by_comp.describe(include = 'all') # incluir tododf.groupby("Company").describe()
Sales
count
mean
std
min
25%
50%
75%
max
Company
FB
3.0
257.666667
85.943780
180.0
211.5
243.0
296.5
350.0
GOOG
3.0
198.333333
77.513440
120.0
160.0
200.0
237.5
275.0
MSFT
3.0
288.000000
145.161978
124.0
232.0
340.0
370.0
400.0
# Una de las funciones mas usadas para descripción estadística de un dataframe# Genera estadísticas descriptivas que resumen la tendencia central, la dispersión# y la forma de la distribución de un conjunto de datos,# excluyendo los valores `` NaN``.# Transponer la descripcióndf.groupby("Company").describe().transpose()
Company
FB
GOOG
MSFT
Sales
count
3.000000
3.000000
3.000000
mean
257.666667
198.333333
288.000000
std
85.943780
77.513440
145.161978
min
180.000000
120.000000
124.000000
25%
211.500000
160.000000
232.000000
50%
243.000000
200.000000
340.000000
75%
296.500000
237.500000
370.000000
max
350.000000
275.000000
400.000000
# Descripción estadística de los datos de la compañía GOOGdf.groupby("Company").describe().transpose()["GOOG"]
Sales count 3.000000
mean 198.333333
std 77.513440
min 120.000000
25% 160.000000
50% 200.000000
75% 237.500000
max 275.000000
Name: GOOG, dtype: float64
Pivot Tables
La funciónlidad “Pivot_table” es muy utilizada y popular en las conocidas “hojas de cálculo” tipo, OpenOffice, LibreOffice, Excel, Lotus, etc. Esta funcionalidad nos permite agrupar, ordenar, calcular datos y manejar datos de una forma muy similar a la que se hace con las hojas de cálculo.
mas informacion
La principal función del “Pivot_table” son las agrupaciones de datos a las que se les suelen aplicar funciones matemáticas como sumatorios, promedios, etc
importseabornassns# importar la librería seaborn# cargar dataset del titanictitanic=sns.load_dataset("titanic")titanic.head()
survived
pclass
sex
age
sibsp
parch
fare
embarked
class
who
adult_male
deck
embark_town
alive
alone
0
0
3
male
22.0
1
0
7.2500
S
Third
man
True
NaN
Southampton
no
False
1
1
1
female
38.0
1
0
71.2833
C
First
woman
False
C
Cherbourg
yes
False
2
1
3
female
26.0
0
0
7.9250
S
Third
woman
False
NaN
Southampton
yes
True
3
1
1
female
35.0
1
0
53.1000
S
First
woman
False
C
Southampton
yes
False
4
0
3
male
35.0
0
0
8.0500
S
Third
man
True
NaN
Southampton
no
True
Haciendo el Pivot table a mano para obtener el promedio de personas que sobrevivieron por genero
# 1. Agrupar por genero# 2. Obtener los sobrevivientes# 3. Calcular el promediotitanic.groupby("sex")[["survived"]].mean()
survived
sex
female
0.742038
male
0.188908
promedio de cuantos sobrevivieron por genero divididos por clase
# 1. Agrupar por genero y clase# 2. Obtener los sobrevivientes# 3. Calcular el promedio# 4. Poner el resultado como una tabla (.unstack)titanic.groupby(["sex","class"],observed=True)["survived"].mean().unstack()
La concatenación básicamente combina DataFrames. Tenga en cuenta que las dimensiones deben coincidir a lo largo del eje con el que se está concatenando.
la Concatenación se hace con dataframes de diferentes indices
Puede usar .concat() y pasar una lista de DataFrames para concatenar juntos:
# Concatenar cada dataframe verticalmente,# ya que coinciden los nombres de las columnaspd.concat([df1,df2,df3],axis="index")
A
B
C
D
0
A0
B0
C0
D0
1
A1
B1
C1
D1
2
A2
B2
C2
D2
3
A3
B3
C3
D3
4
A4
B4
C4
D4
5
A5
B5
C5
D5
6
A6
B6
C6
D6
7
A7
B7
C7
D7
8
A8
B8
C8
D8
9
A9
B9
C9
D9
10
A10
B10
C10
D10
11
A11
B11
C11
D11
# concatenar dataframe horizontalmente,# como no coinciden los index observar lo que ocurrepd.concat([df1,df2,df3],axis="columns")
A
B
C
D
A
B
C
D
A
B
C
D
0
A0
B0
C0
D0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1
A1
B1
C1
D1
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2
A2
B2
C2
D2
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
3
A3
B3
C3
D3
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4
NaN
NaN
NaN
NaN
A4
B4
C4
D4
NaN
NaN
NaN
NaN
5
NaN
NaN
NaN
NaN
A5
B5
C5
D5
NaN
NaN
NaN
NaN
6
NaN
NaN
NaN
NaN
A6
B6
C6
D6
NaN
NaN
NaN
NaN
7
NaN
NaN
NaN
NaN
A7
B7
C7
D7
NaN
NaN
NaN
NaN
8
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
A8
B8
C8
D8
9
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
A9
B9
C9
D9
10
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
A10
B10
C10
D10
11
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
A11
B11
C11
D11
Fusion (Merging)
La función merge() le permite fusionar DataFrames juntos utilizando una lógica similar a la combinación de Tablas SQL. Por ejemplo:
# DataFrames de ejemplo para mergingleft=pd.DataFrame({"Producto":["Arepas","Banano","Cafe"],"Tienda":[1,2,1],"Ventas":[100,200,50],})right=pd.DataFrame({"Producto":["Arepas","Banano","Cafe"],"Tienda":[1,2,1],"Inventario":[50,100,75],})
left
Producto
Tienda
Ventas
0
Arepas
1
100
1
Banano
2
200
2
Cafe
1
50
right
Producto
Tienda
Inventario
0
Arepas
1
50
1
Banano
2
100
2
Cafe
1
75
# how='inner' utilice la intersección de las claves de ambos marcos,# similar a una combinación interna de SQL; las keys son comunespd.merge(left,right,how="inner",on="Producto")
Producto
Tienda_x
Ventas
Tienda_y
Inventario
0
Arepas
1
100
1
50
1
Banano
2
200
2
100
2
Cafe
1
50
1
75
Un ejemplo mas complicado:
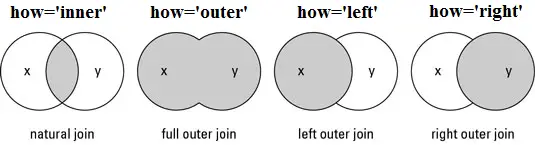
Natural join: para mantener solo las filas que coinciden con los marcos de datos, especifique el argumento how = ‘inner’.
Full outer join: para mantener todas las filas de ambos dataframe, especifique how = ‘OUTER’.
Left outer join: para incluir todas las filas de su dataframe x y solo aquellas de y que coincidan, especifique how=‘left’.
Right outer join: para incluir todas las filas de su dataframe y y solo aquellas de x que coincidan, especifique how=‘right’.
# Creando primero los datos y luego convirtiéndolos en categóricosdf_cate=pd.DataFrame({"Fruta":["manzana","banano","corozo","manzana","pera"]})df_cate
Fruta
0
manzana
1
banano
2
corozo
3
manzana
4
pera
# Observar los tipos de datos en el data framedf_cate.dtypes
Cuando se trabaja con datos, es posible que se encuentre con un DataFrame donde el tipo de datos de una columna no es la correcta. los tipos de datos son principalmente: numericos, categoricos nominales, categoricos ordinales, booleanos, fechas y tiempos, texto.
Se debe convertir los tipos de datos para que sean apropiados para el tipo de datos que representan. Por ejemplo, es posible que desee convertir una columna de strings que representan números en números enteros o flotantes. O puede tener una columna de números que representan fechas, pero que pandas no reconoce como fechas.
Nota: al convertir los datos a su forma correcta, normalmente hace que los DataFrames sean mucho más pequeños en la memoria, lo que los hace más eficientes de usar.
importseabornassns# importar la librería seaborntitanic=sns.load_dataset("titanic")titanic.info()
# convertir la columna sex, embarked, who, embark_town en categóricascols_categoricas_nom=["sex","embarked","who","embark_town"]# ver los datos únicos de las columnas_categoricas_nomforcolumnaincols_categoricas_nom:print(f"Valores únicos en {columna}: {titanic[columna].unique()}")
Valores únicos en sex: ['male' 'female']
Valores únicos en embarked: ['S' 'C' 'Q' nan]
Valores únicos en who: ['man' 'woman' 'child']
Valores únicos en embark_town: ['Southampton' 'Cherbourg' 'Queenstown' nan]
titanic[cols_categoricas_nom]=titanic[cols_categoricas_nom].astype("category")# ver los datos únicos de las columnas_categoricas_nomforcolumnaincols_categoricas_nom:print(f"Valores únicos en {columna}: {titanic[columna].unique()}")
# data frame con algunos datos faltantes# NaN = Not a Numberdf=pd.DataFrame({"A":[1,2,np.nan],"B":[5,np.nan,np.nan],"C":[1,2,3]})df
A
B
C
0
1.0
5.0
1
1
2.0
NaN
2
2
NaN
NaN
3
Detectar si Faltan datos
# verificar cuales valores son NaN o nulos (Null)df.isna()
A
B
C
0
False
False
False
1
False
True
False
2
True
True
False
# Verificar si hay datos faltantes por columnadf.isna().any()
A True
B True
C False
dtype: bool
Numero de datos faltantes
Calcular el numero de datos nulos que hay por columna
# Numero de datos faltantes por columnadf.isna().sum()
A 1
B 2
C 0
dtype: int64
Eliminar datos Faltantes
# Eliminar todas las filas que tengan datos faltantesdf.dropna(axis="index")# cuando son filas no es necesario escribir axis='index'
A
B
C
0
1.0
5.0
1
# Eliminar todas las columnas que tengan datos faltantesdf.dropna(axis="columns")
C
0
1
1
2
2
3
# eliminar las filas que tengas 2 o mas valores NaNdf.dropna(thresh=2)
A
B
C
0
1.0
5.0
1
1
2.0
NaN
2
Reemplazar los datos faltantes
# Llenar los datos faltantes con el dato que nos interesedf.fillna(value="Llenar Valores")# llenar los espacios con un string# puede ser una palabra, numero , etc
A
B
C
0
1.0
5.0
1
1
2.0
Llenar Valores
2
2
Llenar Valores
Llenar Valores
3
# Llenar los datos faltantes con el dato que nos interesedf.fillna(value=99)# llenar los espacios con un numero
A
B
C
0
1.0
5.0
1
1
2.0
99.0
2
2
99.0
99.0
3
# Llenar los datos faltantes con el promedio de esa columnadf["A"].fillna(value=df["A"].mean())
0 1.0
1 2.0
2 1.5
Name: A, dtype: float64
# Llenar los datos faltantes con el promedio de cada columnadf.fillna(value=df.mean())
A
B
C
0
1.0
5.0
1
1
2.0
5.0
2
2
1.5
5.0
3
Datos unicos (Unique Values)
# crear un dataframedf=pd.DataFrame({"col1":[1,2,3,4],"col2":[444,555,666,444],"col3":["abc","def","ghi","xyz"],})df
col1
col2
col3
0
1
444
abc
1
2
555
def
2
3
666
ghi
3
4
444
xyz
# valores únicos de la columna col2df["col2"].unique()
array([444, 555, 666])
# Numero de valores únicos en el dataframedf["col2"].nunique()
3
# contar cuanto se repiten cada uno de los valoresdf["col2"].value_counts()
col2
444 2
555 1
666 1
Name: count, dtype: int64
Datos Duplicados
Se puede borrar los registros que son exactamente iguales en todos los valores de las columnas
Se pueden borrar los valores que se repitan solamente verificando la columna
# crear un dataframedf=pd.DataFrame({"col1":[1,2,3,4],"col2":[444,555,666,444],"col3":["mama "," papa"," HIJO ","HiJa"],})df.head()# solamente mostrar los primeros elementos del dataframe
col1
col2
col3
0
1
444
mama
1
2
555
papa
2
3
666
HIJO
3
4
444
HiJa
métodos Basicos Pandas
Ejemplos simples de los métodos de los dataframe de pandas
Para información completa de los métodos de computacion y estadisticos ver:
Los calculos de las medidas estadisticas se hacen siempre en columnas, es algo predeterminado, si se quiere hacer por filas, se debe especificar dentro de los métodos el parametro axis=1.
Ejemplo:
Calculo de la media por columnas (predeterminado) = df.mean()
Calculo de la media por filas = df.mean(axis='columns')
Esto funciona con los otros tipos de medidas estadisticas
# Se tomara la columna 'mpg' para realizar los cálculosX=data["mpg"]type(X)
pandas.core.series.Series
Medidas de centralizacion
estas funciones se aplican sobre un dataframe de pandas
Media
# Media AritméticaX.mean()
23.514572864321607
# Media aritmética en un dataframedata.mean(numeric_only=True)
# Coeficiente de VariaciónX.std(numeric_only=True)/X.mean(numeric_only=True)
0.33238895546450203
Medidas de Asimetria
Asimetria de Fisher (skewness)
La asimetría es la medida que indica la simetría de la distribución de una variable respecto a la media aritmética, sin necesidad de hacer la representación gráfica. Los coeficientes de asimetría indican si hay el mismo número de elementos a izquierda y derecha de la media.
Existen tres tipos de curva de distribución según su asimetría:
Asimetría negativa: la cola de la distribución se alarga para valores inferiores a la media.
Simétrica: hay el mismo número de elementos a izquierda y derecha de la media. En este caso, coinciden la media, la mediana y la moda. La distribución se adapta a la forma de la campana de Gauss, o distribución normal.
Asimetría positiva: la cola de la distribución se alarga para valores superiores a la media.
# unbiased skew, Normalized by N-1X.skew()
0.45706634399491913
# unbiased skew, Normalized by N-1 en un dataframedata.skew(numeric_only=True)
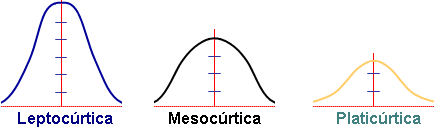
Esta medida determina el grado de concentración que presentan los valores en la región central de la distribución. Por medio del Coeficiente de Curtosis, podemos identificar si existe una gran concentración de valores (Leptocúrtica), una concentración normal (Mesocúrtica) ó una baja concentración (Platicúrtica).
# unbiased kurtosis over requested axis using Fisher's definitionX.kurtosis()
-0.5107812652123154
# unbiased kurtosis over requested axis using Fisher's definition# en un dataframedata.kurtosis(numeric_only=True)
Nota: Recordar que la mayoria de los métodos NO son inplace
df
col1
col2
col3
0
1
444
mama
1
2
555
papa
2
3
666
HIJO
3
4
444
HiJa
Algunos ejemplos de métodos en strings en las columnas
# convertir strings en minúsculadf["col3"].str.lower()
0 mama
1 papa
2 hijo
3 hija
Name: col3, dtype: object
# convertir strings en Mayúsculadf["col3"].str.upper()
0 MAMA
1 PAPA
2 HIJO
3 HIJA
Name: col3, dtype: object
# Eliminar los espacios de los stringsdf["col3"].str.strip()
0 mama
1 papa
2 HIJO
3 HiJa
Name: col3, dtype: object
Transformacion de Variables
Crear variables Dummy: convertir de categoría a númerica
Discretización o Binning: convertir de número a categoría
Columnas Dummy
Convertir variables categoricas a numericas
# crear datos categóricosraw_data={"first_name":["Jason","Molly","Tina","Jake","Amy"],"last_name":["Miller","Jacobson","Ali","Milner","Cooze"],"sex":["male","female","male","female","female"],}df=pd.DataFrame(raw_data,columns=["first_name","last_name","sex"])df
first_name
last_name
sex
0
Jason
Miller
male
1
Molly
Jacobson
female
2
Tina
Ali
male
3
Jake
Milner
female
4
Amy
Cooze
female
# Crear un set de variables dummy para la columna sexdf_sex=pd.get_dummies(df["sex"])df_sex
female
male
0
False
True
1
True
False
2
False
True
3
True
False
4
True
False
# unir los dos dataframesdf_new=df.join(df_sex)df_new
Pandas puede leer una variedad de tipos de archivos usando sus métodos pd.read_mas informacion
CSV
Parquet (Formato recomendado)
Excel
Json
Html
SQL
Nota: estos se ejemplos se hacen con archivos previamente creados para la demostracion
CSV File (comma-separated values)
Este es un formato muy común para compartir datos. Los archivos CSV son archivos de texto, sin formato, que usan comas para separar filas.
Sus desventajas son que no especifican tipos de datos, no admiten datos faltantes, entre otros.
No es un formato ideal para compartir datos.
CSV Input
# Leer archivos separados por comas, extension .csvdf_supermarket_csv=pd.read_csv("supermarkets.csv")df_supermarket_csv.sample(5)
ID
Address
City
State
Country
Name
Employees
4
5
1056 Sanchez St
San Francisco
California
USA
Sanchez
12
3
4
3995 23rd St
San Francisco
CA 94114
USA
Ben's Shop
10
1
2
735 Dolores St
San Francisco
CA 94119
USA
Bready Shop
15
0
1
3666 21st St
San Francisco
CA 94114
USA
Madeira
8
5
6
551 Alvarado St
San Francisco
CA 94114
USA
Richvalley
20
CSV Output
# Grabar el dataframe como archivo separado por comasdf_supermarket_csv.to_csv("example_out.csv",index=False)
Parquet
Este es un formato de archivo binario de columna que es muy bueno para compartir datos. Es muy eficiente en el espacio y el tiempo de lectura.
Es el formato recomendado para compartir datos.
pip install pyarrow
Parquet Input
# Leer archivos separados por comas, extension .csvdf_supermarket_parquet=pd.read_parquet("supermarkets.parquet")df_supermarket_parquet.sample(5)
ID
Address
City
State
Country
Name
Employees
2
3
332 Hill St
San Francisco
California 94114
USA
Super River
25
0
1
3666 21st St
San Francisco
CA 94114
USA
Madeira
8
5
6
551 Alvarado St
San Francisco
CA 94114
USA
Richvalley
20
3
4
3995 23rd St
San Francisco
CA 94114
USA
Ben's Shop
10
4
5
1056 Sanchez St
San Francisco
California
USA
Sanchez
12
Parquet Output
# Grabar el dataframe como archivo parquetdf_supermarket_parquet.to_parquet("example_out.parquet")
Archivo de texto separado por otro caracter
# este archivo los valores están separados por ;df_supermarket=pd.read_csv("supermarkets-semi-colons.txt",sep=";")df_supermarket
ID
Address
City
State
Country
Name
Employees
0
1
3666 21st St
San Francisco
CA 94114
USA
Madeira
8
1
2
735 Dolores St
San Francisco
CA 94119
USA
Bready Shop
15
2
3
332 Hill St
San Francisco
California 94114
USA
Super River
25
3
4
3995 23rd St
San Francisco
CA 94114
USA
Ben's Shop
10
4
5
1056 Sanchez St
San Francisco
California
USA
Sanchez
12
5
6
551 Alvarado St
San Francisco
CA 94114
USA
Richvalley
20
Excel
Pandas puede leer y escribir archivos de Excel, tenga en cuenta que esto solo importa datos. No fórmulas o imágenes, que tengan imágenes o macros pueden hacer que este método read_excel se bloquee.
Es necesario isntalar la libreria openpyxl
pip install openpyxl
Excel Input
# leer un archivo de exceldf_supermarket_excel=pd.read_excel("supermarkets.xlsx",sheet_name=0,# leer la primera hoja del archivo)df_supermarket_excel.sample(5)
JSON (JavaScript Object Notation - Notación de Objetos de JavaScript) es un formato ligero de intercambio de datos. Leerlo y escribirlo es simple para humanos, mientras que para las máquinas es simple interpretarlo y generarlo.
Json Input
# los archivos pueden estar en un link de internetdf_supermarket_json=pd.read_json("http://pythonhow.com/supermarkets.json")df_supermarket_json.sample(5)
Address
City
Country
Employees
ID
Name
State
3
3995 23rd St
San Francisco
USA
10
4
Ben's Shop
CA 94114
2
332 Hill St
San Francisco
USA
25
3
Super River
California 94114
0
3666 21st St
San Francisco
USA
8
1
Madeira
CA 94114
4
1056 Sanchez St
San Francisco
USA
12
5
Sanchez
California
5
551 Alvarado St
San Francisco
USA
20
6
Richvalley
CA 94114
Json output
# Para grabardf_supermarket_json.to_json("Salida.json")
HTML
Pandas puede leer tablas de html
Es necesario instalar las librerias pip install lxml html5lib
La función pandas read_html leerá las tablas de una página web y devolverá una lista de objetos DataFrame:
El módulo pandas.io.sql proporciona una colección de contenedores de consultas para facilitar la recuperación de datos y reducir la dependencia de la API específica de DB. La abstracción de la base de datos es proporcionada por SQLAlchemy si está instalado. Además, necesitará una biblioteca de controladores para su base de datos. Ejemplos de tales controladores son psycopg2 para PostgreSQL o pymysql para MySQL. Para SQLite esto está incluido en la biblioteca estándar de Python por defecto. Puede encontrar una descripción general de los controladores admitidos para cada lenguaje SQL en los documentos de SQLAlchemy.
pip install sqlalchemy
Vea también algunos ejemplos de libros para algunas estrategias avanzadas.
las funciones claves son:
read_sql_table(table_name, con[, schema, …])
Read SQL database table into a DataFrame.
read_sql_query(sql, con[, index_col, …])
Read SQL query into a DataFrame.
read_sql(sql, con[, index_col, …])
Read SQL query or database table into a DataFrame.
DataFrame.to_sql(name, con[, flavor, …])
Write records stored in a DataFrame to a SQL database.
# librerías para crear un proceso de sql sencillofromsqlalchemyimportcreate_engine
# crear un proceso en memoriaengine=create_engine("sqlite:///:memory:")
data_table_web[0].to_sql("data",engine)# grabar el dataframe en formato sql
10
sql_df=pd.read_sql("data",con=engine)# definir la conexión