Por Jose R. Zapata
Ultima actualizacion: 17/Nov/2023

Importar librerias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
información de los Datos
Titanic dataset
Fuente: https://www.kaggle.com/francksylla/titanic-machine-learning-from-disaster
titanic_df = pd.read_csv("https://www.openml.org/data/get_csv/16826755/phpMYEkMl")
titanic_df.sample(10)
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 855 | 3 | 0 | Hassan, Mr. Houssein G N | male | 11 | 0 | 0 | 2699 | 18.7875 | ? | C | ? | ? | ? |
| 30 | 1 | 0 | Blackwell, Mr. Stephen Weart | male | 45 | 0 | 0 | 113784 | 35.5 | T | S | ? | ? | Trenton, NJ |
| 329 | 2 | 1 | Angle, Mrs. William A (Florence 'Mary' Agnes H... | female | 36 | 1 | 0 | 226875 | 26 | ? | S | 11 | ? | Warwick, England |
| 853 | 3 | 0 | Harmer, Mr. Abraham (David Lishin) | male | 25 | 0 | 0 | 374887 | 7.25 | ? | S | B | ? | ? |
| 1076 | 3 | 0 | O'Donoghue, Ms. Bridget | female | ? | 0 | 0 | 364856 | 7.75 | ? | Q | ? | ? | ? |
| 445 | 2 | 0 | Hiltunen, Miss. Marta | female | 18 | 1 | 1 | 250650 | 13 | ? | S | ? | ? | Kontiolahti, Finland / Detroit, MI |
| 1051 | 3 | 0 | Nancarrow, Mr. William Henry | male | 33 | 0 | 0 | A./5. 3338 | 8.05 | ? | S | ? | ? | ? |
| 116 | 1 | 1 | Fortune, Mrs. Mark (Mary McDougald) | female | 60 | 1 | 4 | 19950 | 263 | C23 C25 C27 | S | 10 | ? | Winnipeg, MB |
| 938 | 3 | 0 | Klasen, Mr. Klas Albin | male | 18 | 1 | 1 | 350404 | 7.8542 | ? | S | ? | ? | ? |
| 734 | 3 | 1 | Coutts, Master. William Loch 'William' | male | 3 | 1 | 1 | C.A. 37671 | 15.9 | ? | S | 2 | ? | England Brooklyn, NY |
titanic_df.shape
(1309, 14)
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 name 1309 non-null object
3 sex 1309 non-null object
4 age 1309 non-null object
5 sibsp 1309 non-null int64
6 parch 1309 non-null int64
7 ticket 1309 non-null object
8 fare 1309 non-null object
9 cabin 1309 non-null object
10 embarked 1309 non-null object
11 boat 1309 non-null object
12 body 1309 non-null object
13 home.dest 1309 non-null object
dtypes: int64(4), object(10)
memory usage: 143.3+ KB
Preparacion de datos
Eliminar columnas no necesarias
Se eliminan las columnas boat y body ya que con esta información solamente ya se puede conocer si una persona sobrevivio o no.
Para el siguiente ejercicio no se tendra en cuenta las columnas name, ticket, cabin y home.dest para hacer el ejercicio mas sencillo.
titanic_df = titanic_df.drop(['boat', 'body', 'home.dest','name', 'ticket', 'cabin'],
axis='columns')
titanic_df.head()
| pclass | survived | sex | age | sibsp | parch | fare | embarked | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | female | 29 | 0 | 0 | 211.3375 | S |
| 1 | 1 | 1 | male | 0.9167 | 1 | 2 | 151.55 | S |
| 2 | 1 | 0 | female | 2 | 1 | 2 | 151.55 | S |
| 3 | 1 | 0 | male | 30 | 1 | 2 | 151.55 | S |
| 4 | 1 | 0 | female | 25 | 1 | 2 | 151.55 | S |
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 sex 1309 non-null object
3 age 1309 non-null object
4 sibsp 1309 non-null int64
5 parch 1309 non-null int64
6 fare 1309 non-null object
7 embarked 1309 non-null object
dtypes: int64(4), object(4)
memory usage: 81.9+ KB
El primer paso que se sugiere es corregir el tipo de datos de las columnas, pero para esta demostracion que solo estara enfocada en los algoritmos de clasificacion se van a eliminar las filas con los datos faltantes primero, en un caso real es necesario tener en cuenta este paso.
Tratamiento de datos nulos
# Contar el numero de datos nulos
titanic_df[titanic_df.isna().any(axis='columns')].count()
pclass 0
survived 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
dtype: int64
titanic_df['age'].unique()
array(['29', '0.9167', '2', '30', '25', '48', '63', '39', '53', '71',
'47', '18', '24', '26', '80', '?', '50', '32', '36', '37', '42',
'19', '35', '28', '45', '40', '58', '22', '41', '44', '59', '60',
'33', '17', '11', '14', '49', '76', '46', '27', '64', '55', '70',
'38', '51', '31', '4', '54', '23', '43', '52', '16', '32.5', '21',
'15', '65', '28.5', '45.5', '56', '13', '61', '34', '6', '57',
'62', '67', '1', '12', '20', '0.8333', '8', '0.6667', '7', '3',
'36.5', '18.5', '5', '66', '9', '0.75', '70.5', '22.5', '0.3333',
'0.1667', '40.5', '10', '23.5', '34.5', '20.5', '30.5', '55.5',
'38.5', '14.5', '24.5', '60.5', '74', '0.4167', '11.5', '26.5'],
dtype=object)
# los datos faltantes estan representados por '?'
titanic_df = titanic_df.replace('?',np.nan)
Numero de datos nulos por columna
titanic_df[titanic_df.isna().any(axis='columns')].count()
pclass 266
survived 266
sex 266
age 3
sibsp 266
parch 266
fare 265
embarked 264
dtype: int64
Limpiar las filas con datos nulos en la columna survived que es la variable objetivo
titanic_df = titanic_df.dropna(subset=['survived'])
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 sex 1309 non-null object
3 age 1046 non-null object
4 sibsp 1309 non-null int64
5 parch 1309 non-null int64
6 fare 1308 non-null object
7 embarked 1307 non-null object
dtypes: int64(4), object(4)
memory usage: 81.9+ KB
Convertir las variables a su formato correcto
Corregir las variables categoricas
cols_categoricas = ["pclass", "sex", "embarked"]
titanic_df[cols_categoricas] = titanic_df[cols_categoricas].astype("category")
Corregir variables categorica ordinal
titanic_df["pclass"] = pd.Categorical(titanic_df["pclass"],
categories=[3, 2, 1],
ordered=True)
Corregir las variables numericas
cols_numericas = ["age", "fare"]
titanic_df[cols_numericas] = titanic_df[cols_numericas].astype("float")
Corregir las variables booleanas
cols_booleanas = ["survived"]
titanic_df[cols_booleanas] = titanic_df[cols_booleanas].astype("bool")
información del dataset
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null category
1 survived 1309 non-null bool
2 sex 1309 non-null category
3 age 1046 non-null float64
4 sibsp 1309 non-null int64
5 parch 1309 non-null int64
6 fare 1308 non-null float64
7 embarked 1307 non-null category
dtypes: bool(1), category(3), float64(2), int64(2)
memory usage: 46.5 KB
Descripcion estadistica
titanic_df.describe()
| age | sibsp | parch | fare | |
|---|---|---|---|---|
| count | 1046.000000 | 1309.000000 | 1309.000000 | 1308.000000 |
| mean | 29.881135 | 0.498854 | 0.385027 | 33.295479 |
| std | 14.413500 | 1.041658 | 0.865560 | 51.758668 |
| min | 0.166700 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 21.000000 | 0.000000 | 0.000000 | 7.895800 |
| 50% | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 39.000000 | 1.000000 | 0.000000 | 31.275000 |
| max | 80.000000 | 8.000000 | 9.000000 | 512.329200 |
titanic_df.head()
| pclass | survived | sex | age | sibsp | parch | fare | embarked | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | True | female | 29.0000 | 0 | 0 | 211.3375 | S |
| 1 | 1 | True | male | 0.9167 | 1 | 2 | 151.5500 | S |
| 2 | 1 | False | female | 2.0000 | 1 | 2 | 151.5500 | S |
| 3 | 1 | False | male | 30.0000 | 1 | 2 | 151.5500 | S |
| 4 | 1 | False | female | 25.0000 | 1 | 2 | 151.5500 | S |
titanic_df.to_parquet('titanic_processed.parquet',
index=False)
análisis Univariable
Se debe hacer un análisis de cada una de las variables y describir sus caracteristicas, solo se visualizara la variable survived que es la variable objetivo para ver si esta balanceada o no.
# visulizar la distribucion de los datos booleanos de la variable survived
titanic_df["survived"].value_counts().plot(kind="bar",
color=['skyblue', 'orange']);
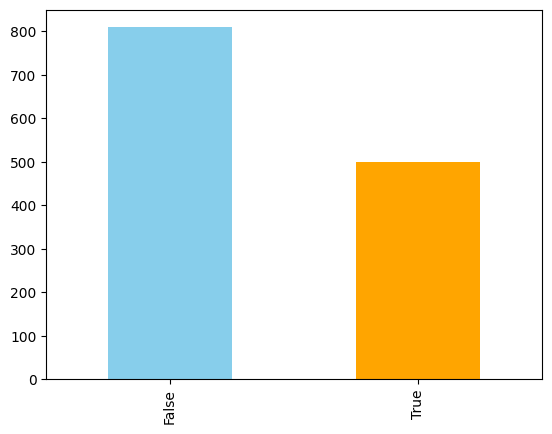
No hay un balance de clases, pero no es tan desbalanceado como para tener que hacer un balanceo de clases.
análisis Bivariable
Se realizara un análisis de la variable de salida con las variables de entrada teniendo en cuenta que la variable objetivo es categorica nominal
Numericas vs Categoricas
cols_numericas
['age', 'fare']
# son 2 variables numericas
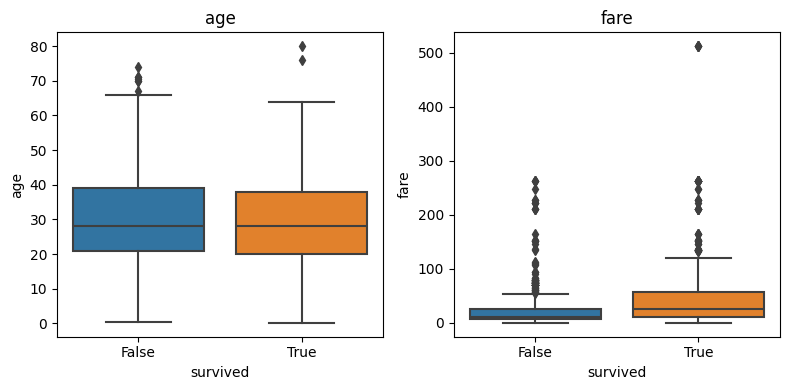
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes = axes.flatten()
for i, col in enumerate(cols_numericas):
sns.boxplot(data=titanic_df,
x="survived", y=col,
ax=axes[i])
axes[i].set_title(col)
plt.tight_layout()
plt.show()
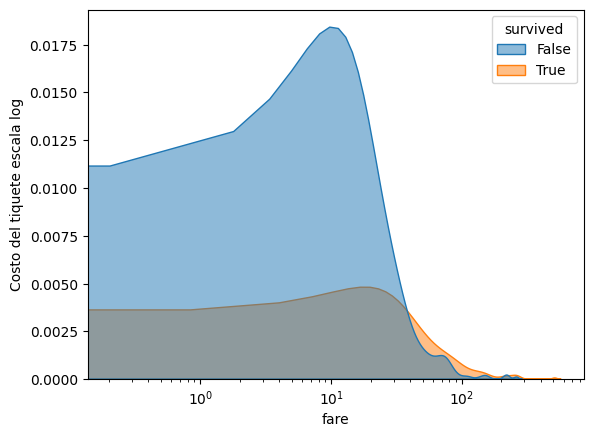
#grafica con seaborn del distribucion de fare por survived
sns.kdeplot(data=titanic_df, x='fare',hue='survived',
alpha=0.5, fill=True);
plt.xscale('log')
plt.ylabel("Costo del tiquete escala log");
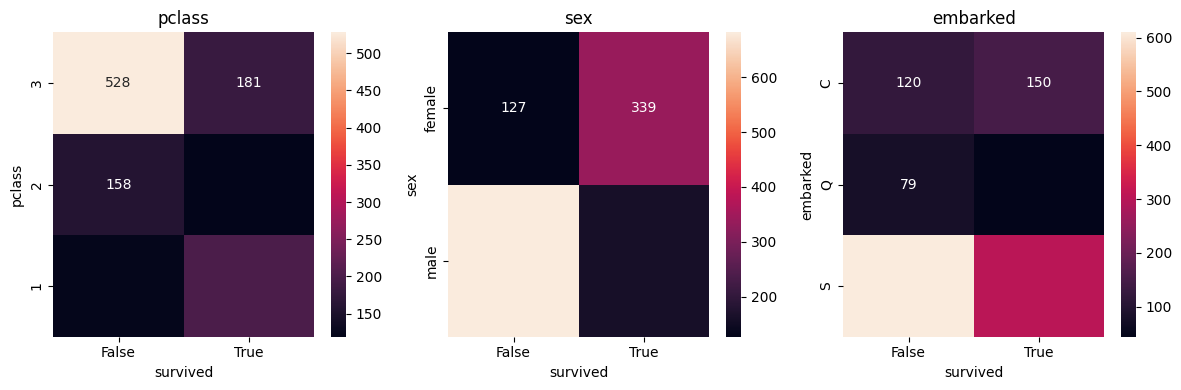
Categoricas vs Categorica
Variables categoricas vs variable de salida
# crear graficas de heatmap para ver la correlacion entre las variables categoricas y la variable survived
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
axes = axes.flatten()
for i, col in enumerate(cols_categoricas):
sns.heatmap(pd.crosstab(titanic_df[col],
titanic_df["survived"]),
annot=True, fmt="d",
ax=axes[i])
axes[i].set_title(col)
plt.tight_layout()
from scipy import stats
resultados_chi2 = []
for col in cols_categoricas:
# Calcular la prueba chi-cuadrado
chi2, pval, dof, expected = stats.chi2_contingency(pd.crosstab(titanic_df[col],
titanic_df["survived"]))
#save calues in pandas dataframe to concatenate with the results of other variables
df = pd.DataFrame({'variable': [col],
'chi2': [chi2],
'pval': [pval]})
resultados_chi2.append(df)
df_chi2 = pd.concat(resultados_chi2, ignore_index=True)
df_chi2
| variable | chi2 | pval | |
|---|---|---|---|
| 0 | pclass | 127.859156 | 1.720826e-28 |
| 1 | sex | 363.617908 | 4.589925e-81 |
| 2 | embarked | 44.241743 | 2.471881e-10 |
Feature Engineering (Ingenieria de caracteristicas)
Se va realizar una imputacion simple sin tener en cuenta un análisis mas profundo de los datos y la distribucion de los mismos.
las variables numericas se imputaran con la media y las variables categoricas con la moda.
# librerias para el preprocesamiento de datos
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null category
1 survived 1309 non-null bool
2 sex 1309 non-null category
3 age 1046 non-null float64
4 sibsp 1309 non-null int64
5 parch 1309 non-null int64
6 fare 1308 non-null float64
7 embarked 1307 non-null category
dtypes: bool(1), category(3), float64(2), int64(2)
memory usage: 46.5 KB
cols_numericas = ["age", "fare", "sibsp", "parch"]
cols_categoricas = ["sex", "embarked"]
cols_categoricas_ord = ["pclass"]
Creacion de pipelines de transformacion, la codificacion es:
OneHotEncoderpara las variables categoricas nominalesOrdinalEncoderpara las variables categoricas ordinales
numeric_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
])
categorical_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())])
categorical_ord_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())])
preprocessor = ColumnTransformer(
transformers=[
('numericas', numeric_pipe, cols_numericas),
('categoricas', categorical_pipe, cols_categoricas),
('categoricas ordinales', categorical_ord_pipe, cols_categoricas_ord)
])
preprocessor
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp', 'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp', 'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare', 'sibsp', 'parch']
SimpleImputer(strategy='median')
['sex', 'embarked']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
Clasificacion Binaria
titanic_df = pd.read_parquet('titanic_processed.parquet')
titanic_df.head()
| pclass | survived | sex | age | sibsp | parch | fare | embarked | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | True | female | 29.0000 | 0 | 0 | 211.3375 | S |
| 1 | 1 | True | male | 0.9167 | 1 | 2 | 151.5500 | S |
| 2 | 1 | False | female | 2.0000 | 1 | 2 | 151.5500 | S |
| 3 | 1 | False | male | 30.0000 | 1 | 2 | 151.5500 | S |
| 4 | 1 | False | female | 25.0000 | 1 | 2 | 151.5500 | S |
titanic_df.shape
(1309, 8)
Dividir el dataset en entrenamiento y prueba
from sklearn.model_selection import train_test_split
X_features = titanic_df.drop('survived', axis='columns')
Y_target = titanic_df['survived']
x_train, x_test, y_train, y_test = train_test_split(X_features,
Y_target,
test_size=0.2,
stratify=Y_target)
x_train.shape, y_train.shape
((1047, 7), (1047,))
x_test.shape, y_test.shape
((262, 7), (262,))
x_train.head()
| pclass | sex | age | sibsp | parch | fare | embarked | |
|---|---|---|---|---|---|---|---|
| 55 | 1 | female | 14.0 | 1 | 2 | 120.0000 | S |
| 1275 | 3 | male | 16.0 | 2 | 0 | 18.0000 | S |
| 463 | 2 | male | 22.0 | 2 | 0 | 31.5000 | S |
| 185 | 1 | male | 42.0 | 0 | 0 | 26.5500 | S |
| 893 | 3 | male | 29.0 | 0 | 0 | 7.8542 | S |
Clasificacion modelo simple
EL siguiente modelo esta basado en reglas, basadas en el análisis univariable y bivariable debido a esto es necesario transformar previamente el dataset de prueba usando el pipeline de transformacion entrenado con el dataset de entrenamiento.
# entrenar el pipeline con los datos de entrenamiento
preprocessor.fit(x_train)
#obtener el nombre de las columnas de salida del preprocesamiento
# usando .get_feature_names_out()
feature_names = preprocessor.get_feature_names_out()
# transform x_Test with preprocessor and pandas output set
x_test_transformed = preprocessor.transform(x_test)
x_test_transformed = pd.DataFrame(x_test_transformed, columns=feature_names)
x_test_transformed.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 262 entries, 0 to 261
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 numericas__age 262 non-null float64
1 numericas__fare 262 non-null float64
2 numericas__sibsp 262 non-null float64
3 numericas__parch 262 non-null float64
4 categoricas__sex_female 262 non-null float64
5 categoricas__sex_male 262 non-null float64
6 categoricas__embarked_C 262 non-null float64
7 categoricas__embarked_Q 262 non-null float64
8 categoricas__embarked_S 262 non-null float64
9 categoricas ordinales__pclass 262 non-null float64
dtypes: float64(10)
memory usage: 20.6 KB
x_test_transformed.sample(5)
| numericas__age | numericas__fare | numericas__sibsp | numericas__parch | categoricas__sex_female | categoricas__sex_male | categoricas__embarked_C | categoricas__embarked_Q | categoricas__embarked_S | categoricas ordinales__pclass | |
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 22.0 | 49.5000 | 0.0 | 2.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 71 | 74.0 | 7.7750 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 2.0 |
| 208 | 27.0 | 10.5000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| 26 | 27.0 | 52.0000 | 1.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 76 | 5.0 | 31.3875 | 4.0 | 2.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 2.0 |
def modelo_basico(input:pd.DataFrame)->bool:
"""
modelo basico que predice si los pasajeros sobrevivieron o no
en base a reglas simples obtenidas del análisis exploratorio
Args:
input (pd.Dataframe) : dataframe con los datos de entrada
Returns:
(bool): prediccion de sobrevivencia
"""
if (input['categoricas__sex_female'] == 1) & (input['categoricas ordinales__pclass'] < 3):
return True
elif (input['numericas__age'] <= 5) | ((input['numericas__age'] >= 10) & (input['numericas__age'] <= 15)):
return True
else:
return False
# predicciones del modelo basico
y_pred = x_test_transformed.apply(modelo_basico, axis='columns')
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(y_test,y_pred);
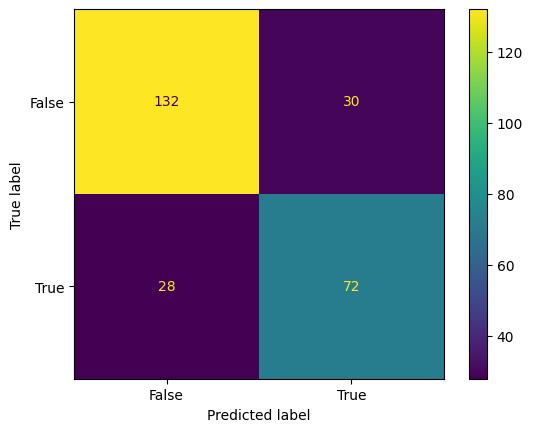
Evaluacion Modelo Simple
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc = roc_auc_score(y_test, y_pred)
print("accuracy_score : ", acc)
print("precision_score : ", prec)
print("recall_score : ", recall)
print("f1_score : ", f1)
print("roc_auc_score : ", roc)
accuracy_score : 0.7786259541984732
precision_score : 0.7058823529411765
recall_score : 0.72
f1_score : 0.712871287128713
roc_auc_score : 0.7674074074074074
Cualquier modelo que se entrene se va evaluar conmas mismas metricas y para ser seleccionado debe ser mejor que el modelo simple.
Regresion Logistica para Clasificacion
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression(penalty='l2',
C=1.0,
solver='liblinear')
logistic_complete = Pipeline(steps=[("preprocessor", preprocessor),
("model", logistic_model)])
logistic_complete.fit(x_train, y_train)
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', LogisticRegression(solver='liblinear'))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', LogisticRegression(solver='liblinear'))])ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp', 'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare', 'sibsp', 'parch']
SimpleImputer(strategy='median')
['sex', 'embarked']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
LogisticRegression(solver='liblinear')
y_pred = logistic_complete.predict(x_test)
Matriz de confusion
ConfusionMatrixDisplay.from_predictions(y_test,y_pred);
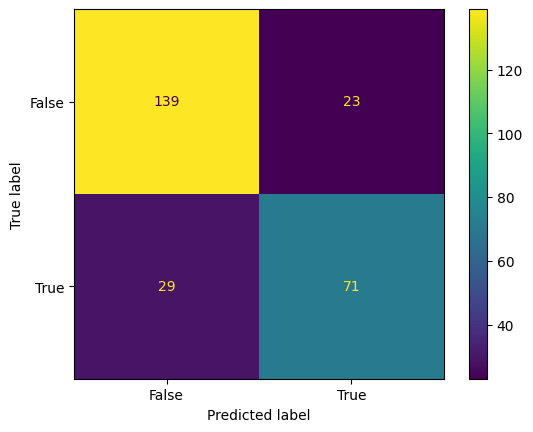
Evaluacion Regresion Logistica
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc = roc_auc_score(y_test, y_pred)
print("accuracy_score : ", acc)
print("precision_score : ", prec)
print("recall_score : ", recall)
print("f1_score : ", f1)
print("roc_auc_score : ", roc)
accuracy_score : 0.8015267175572519
precision_score : 0.7553191489361702
recall_score : 0.71
f1_score : 0.731958762886598
roc_auc_score : 0.7840123456790123
Clasificacion con Multiples Modelos
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import SGDClassifier
from sklearn.svm import LinearSVC
from sklearn.neighbors import RadiusNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
titanic_df = pd.read_parquet('titanic_processed.parquet')
x_train.columns
Index(['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked'], dtype='object')
FEATURES = list(x_train.columns)
FEATURES
['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']
result_dict = {}
funciones de ayuda
def summarize_classification(y_test, y_pred):
acc = accuracy_score(y_test, y_pred, normalize=True)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc = roc_auc_score(y_test, y_pred)
return {'accuracy': acc,
'precision': prec,
'recall':recall,
'f1':f1,
'roc':roc
}
La siguiente función permite definir todos los pasos de entrenamiento y evaluacion que son los mismos para todos los modelos que se van a probar.
def build_model(classifier_fn,
name_of_y_col: str,
names_of_x_cols: list,
dataset: pd.DataFrame,
test_frac:float =0.2)-> dict:
"""
función para entrenar un modelo de clasificacion
Args:
classifier_fn: función de clasificacion
name_of_y_col (list): nombre de la columna objetivo
names_of_x_cols (list): lista de nombres de las columnas de caracteristicas
dataset (pd.Dataframe): dataframe con los datos
test_frac (float): fraccion de datos para el test, por defecto 0.2
Returns:
dict: diccionario con las metricas de desempeño del modelo en train y test
"""
# separar las columnas de caracteristicas y la columna objetivo
X = dataset[names_of_x_cols]
Y = dataset[name_of_y_col]
# dividir los datos en train y test
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=test_frac)
# crear el pipeline con el preprocesamiento y el modelo de clasificacion
classifier_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", classifier_fn)])
# entrenar el pipeline del clasificador
model = classifier_pipe.fit(x_train, y_train)
# predecir los datos de test
y_pred = model.predict(x_test)
# predecir los datos de train
y_pred_train = model.predict(x_train)
# calcular las metricas de desempeño
train_summary = summarize_classification(y_train, y_pred_train)
test_summary = summarize_classification(y_test, y_pred)
# guardar las metricas de desempeño en un dataframe
pred_results = pd.DataFrame({'y_test': y_test,
'y_pred': y_pred})
# calcular la matriz de confusion
model_crosstab = pd.crosstab(pred_results.y_pred, pred_results.y_test)
return {'train': train_summary,
'test': test_summary,
'confusion_matrix': model_crosstab}
Regresion logistica
result_dict['logistic'] = build_model(LogisticRegression(solver='liblinear'),
'survived',
FEATURES,
titanic_df)
result_dict['logistic']
{'train': {'accuracy': 0.792741165234002,
'precision': 0.7364130434782609,
'recall': 0.6930946291560103,
'f1': 0.7140974967061924,
'roc': 0.7726143877487368},
'test': {'accuracy': 0.7900763358778626,
'precision': 0.78125,
'recall': 0.6880733944954128,
'f1': 0.7317073170731707,
'roc': 0.7754092462673143},
'confusion_matrix': y_test False True
y_pred
False 132 34
True 21 75}
Lineal Discriminant Analysis
result_dict['linear_discriminant_analysis'] = build_model(LinearDiscriminantAnalysis(solver='svd'),
'survived',
FEATURES,
titanic_df)
result_dict['linear_discriminant_analysis']
{'train': {'accuracy': 0.7831900668576887,
'precision': 0.734375,
'recall': 0.6928746928746928,
'f1': 0.7130214917825537,
'roc': 0.7667498464373464},
'test': {'accuracy': 0.8206106870229007,
'precision': 0.7555555555555555,
'recall': 0.7311827956989247,
'f1': 0.7431693989071038,
'roc': 0.8005026404530127},
'confusion_matrix': y_test False True
y_pred
False 147 25
True 22 68}
result_dict['linear_discriminant_analysis'] = build_model(LinearDiscriminantAnalysis(solver='svd'),
'survived',
FEATURES,
titanic_df)
result_dict['linear_discriminant_analysis']
{'train': {'accuracy': 0.7975167144221585,
'precision': 0.7472826086956522,
'recall': 0.6979695431472082,
'f1': 0.7217847769028872,
'roc': 0.777774970654768},
'test': {'accuracy': 0.7480916030534351,
'precision': 0.7127659574468085,
'recall': 0.6320754716981132,
'f1': 0.67,
'roc': 0.729499274310595},
'confusion_matrix': y_test False True
y_pred
False 129 39
True 27 67}
SGD
result_dict['sgd'] = build_model(SGDClassifier(max_iter=1000,
tol=1e-3),
'survived',
FEATURES,
titanic_df)
result_dict['sgd']
{'train': {'accuracy': 0.7182425978987583,
'precision': 0.636604774535809,
'recall': 0.6030150753768844,
'f1': 0.6193548387096773,
'roc': 0.6959605423109384},
'test': {'accuracy': 0.732824427480916,
'precision': 0.7051282051282052,
'recall': 0.5392156862745098,
'f1': 0.611111111111111,
'roc': 0.6977328431372547},
'confusion_matrix': y_test False True
y_pred
False 137 47
True 23 55}
SVC Lineal
https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html
- SVC con kernel lineal
- dual=False cuando el numero de muestras > numero de caracteristicas
result_dict['linear_svc'] = build_model(LinearSVC(C=1.0,
max_iter=1000,
tol=1e-3,
dual=False),
'survived',
FEATURES,
titanic_df)
result_dict['linear_svc']
{'train': {'accuracy': 0.7908309455587392,
'precision': 0.7317073170731707,
'recall': 0.6923076923076923,
'f1': 0.7114624505928854,
'roc': 0.7708113804004215},
'test': {'accuracy': 0.7786259541984732,
'precision': 0.7653061224489796,
'recall': 0.6818181818181818,
'f1': 0.721153846153846,
'roc': 0.7652511961722488},
'confusion_matrix': y_test False True
y_pred
False 129 35
True 23 75}
Radius Neighbors Classifier
result_dict['radius_neighbors'] = build_model(RadiusNeighborsClassifier(radius=40.0),
'survived',
FEATURES,
titanic_df)
result_dict['radius_neighbors']
{'train': {'accuracy': 0.6685768863419294,
'precision': 0.6736111111111112,
'recall': 0.24433249370277077,
'f1': 0.3585951940850277,
'roc': 0.5860124006975392},
'test': {'accuracy': 0.6297709923664122,
'precision': 0.575,
'recall': 0.22330097087378642,
'f1': 0.32167832167832167,
'roc': 0.5581913659400378},
'confusion_matrix': y_test False True
y_pred
False 142 80
True 17 23}
Decision Tree classifier
result_dict['decision_tree'] = build_model(DecisionTreeClassifier(),
'survived',
FEATURES,
titanic_df)
result_dict['decision_tree']
{'train': {'accuracy': 0.9637058261700095,
'precision': 0.9811320754716981,
'recall': 0.9215189873417722,
'f1': 0.9503916449086162,
'roc': 0.9553913955113769},
'test': {'accuracy': 0.8396946564885496,
'precision': 0.8315789473684211,
'recall': 0.7523809523809524,
'f1': 0.79,
'roc': 0.8252350621777373},
'confusion_matrix': y_test False True
y_pred
False 141 26
True 16 79}
Naive Bayes
result_dict['naive_bayes'] = build_model(GaussianNB(),
'survived',
FEATURES,
titanic_df)
result_dict['naive_bayes']
{'train': {'accuracy': 0.7793696275071633,
'precision': 0.7126168224299065,
'recall': 0.738498789346247,
'f1': 0.7253269916765755,
'roc': 0.772246240098991},
'test': {'accuracy': 0.7938931297709924,
'precision': 0.6896551724137931,
'recall': 0.6896551724137931,
'f1': 0.6896551724137931,
'roc': 0.7676847290640394},
'confusion_matrix': y_test False True
y_pred
False 148 27
True 27 60}
Comparacion de modelos
# Crear un diccionario solo con los resultados de prueba de cada modelo
nombre_modelos = result_dict.keys()
resultados_train = {} # crear diccionario vacio
resultados_test = {} # crear diccionario vacio
for nombre in nombre_modelos:
resultados_train[nombre] = result_dict[nombre]['train']['f1']
resultados_test[nombre] = result_dict[nombre]['test']['f1']
df_comparacion = pd.DataFrame([resultados_train, resultados_test], index=['train', 'test'])
# Plot the bar chart
fig, ax = plt.subplots(figsize=(10, 4))
df_comparacion.T.plot(kind='bar', ax=ax)
# Adjust the layout
ax.set_ylabel('F1 score')
ax.set_title('Model F1 Comparison')
# Set the x-tick labels inside the bars and rotate by 90 degrees
ax.set_xticks(range(len(df_comparacion.columns)))
ax.set_xticklabels([])
# Draw the x-tick labels inside the bars rotated by 90 degrees
for i, label in enumerate(df_comparacion.columns):
bar_center = (df_comparacion.loc['train', label] +
df_comparacion.loc['test', label]) / 2
ax.text(i, bar_center, label, ha='center',
va='center_baseline', rotation=45)
plt.tight_layout()
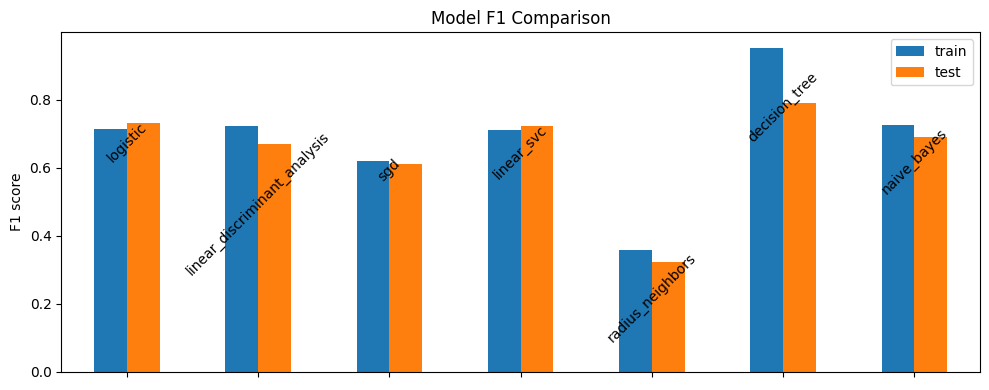
Cross Validation - Seleccion de Modelos
Analizar la varianza de los resultados para obtener los que tengan mejor resultado.
Con el cross validation se puede detectar si el modelo esta sobreajustado o no.
# Grabar los resultados de cada modelo
from sklearn import model_selection
models = []
#logistic Regression
models.append(('Logistic', LogisticRegression(solver='liblinear')))
# Decision Tree classifier
models.append(('Decision Tree', DecisionTreeClassifier()))
#
models.append(('LDA', LinearDiscriminantAnalysis(solver= 'svd')))
# evaluate each model in turn
results = []
names = []
scoring = 'f1'
for name, model in models:
# Kfol cross validation for model selection
kfold = model_selection.KFold(n_splits=10)
model_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", model)])
#X train , y train
cv_results = model_selection.cross_val_score(model_pipe,
x_train, y_train,
cv=kfold,
scoring=scoring)
results.append(cv_results)
names.append(name)
msg = f"({name}, {cv_results.mean()}, {cv_results.std()}"
print(msg)
(Logistic, 0.7021797259716466, 0.04878880609448707
(Decision Tree, 0.6448902869325651, 0.06141106864049656
(LDA, 0.7024526448038142, 0.04725740067640807
plt.figure(figsize = (15,8))
result_df = pd.DataFrame(results, index=names).T
result_df.boxplot()
plt.title("Resultados de Cross Validation");
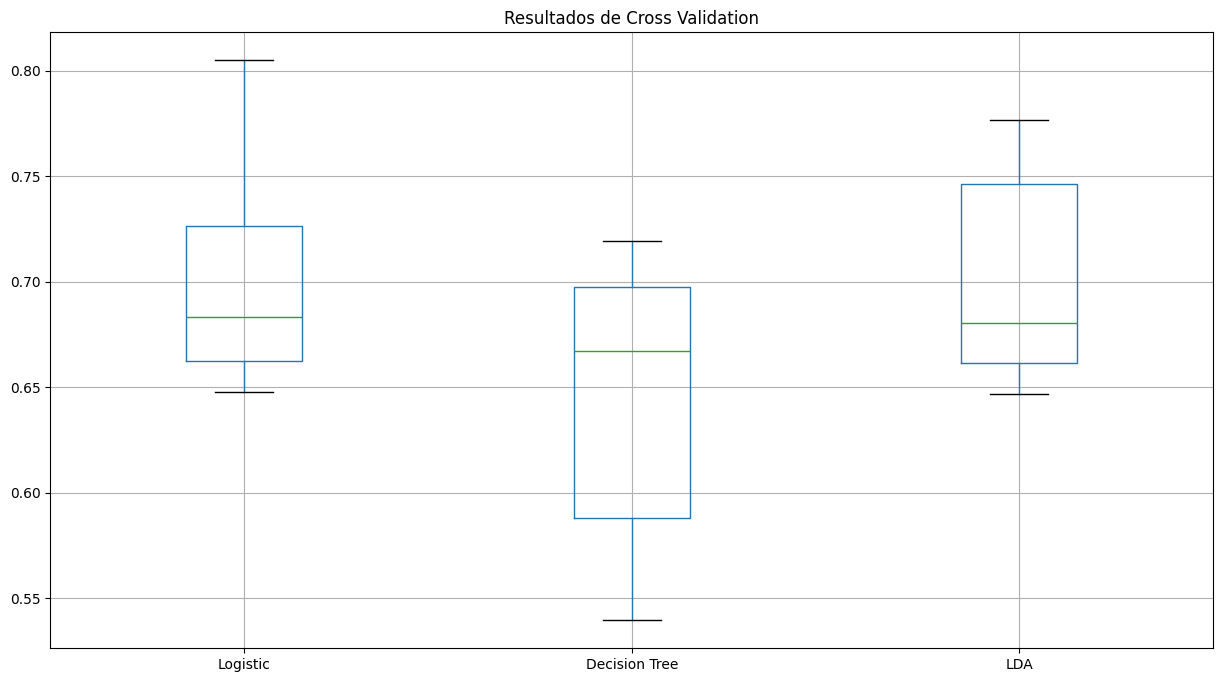
Comparacion Estadistica de Modelos
from scipy.stats import f_oneway
model1 = result_df['Logistic']
model2 = result_df['Decision Tree']
model3 = result_df['LDA']
statistic, p_value = f_oneway(model1, model2, model3)
print(f'Statistic: {statistic}')
print(f'p_value: {p_value}')
alpha = 0.05 # nivel de significancia
if p_value < alpha:
print("Existe una diferencia estadísticamente significativa en los resultados de cross-validation de los modelos.")
else:
print("No Existe una diferencia estadísticamente significativa en los resultados de cross-validation de los modelos.")
Statistic: 3.539696943277524
p_value: 0.043129128040821176
Existe una diferencia estadísticamente significativa en los resultados de cross-validation de los modelos.
Hyperparameter tunning (Optimizacion de hiperparametros)
titanic_df = pd.read_parquet('titanic_processed.parquet')
X = titanic_df.drop('survived', axis='columns')
Y = titanic_df['survived']
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
def summarize_classification(y_test, y_pred):
acc = accuracy_score(y_test, y_pred, normalize=True)
f1 = f1_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
roc = roc_auc_score(y_test, y_pred)
print("Test data count: ",len(y_test))
print("f1_score : " , f1)
print("accuracy_score : " , acc)
print("precision_score : " , prec)
print("recall_score : ", recall)
print("roc_auc_score : ", roc)
Decision Tree
from sklearn.model_selection import GridSearchCV
# cuando se usan pipelines se debe usar
# el nombre del paso y luego __ y el parametro
parameters = {'model__max_depth': [4, 5, 7, 9, 10],
'model__max_features': [2, 3, 4, 5, 6, 7, 8, 9],
'model__criterion': ['gini', 'entropy'],
}
DecisionTree_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", DecisionTreeClassifier())])
grid_search = GridSearchCV(DecisionTree_pipe,
parameters, cv=3,
scoring='f1',
return_train_score=True)
grid_search.fit(x_train, y_train)
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age',
'fare',
'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex',
'embarked']),
('categoricas '
'ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', DecisionTreeClassifier())]),
param_grid={'model__criterion': ['gini', 'entropy'],
'model__max_depth': [4, 5, 7, 9, 10],
'model__max_features': [2, 3, 4, 5, 6, 7, 8, 9]},
return_train_score=True, scoring='f1')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age',
'fare',
'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex',
'embarked']),
('categoricas '
'ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', DecisionTreeClassifier())]),
param_grid={'model__criterion': ['gini', 'entropy'],
'model__max_depth': [4, 5, 7, 9, 10],
'model__max_features': [2, 3, 4, 5, 6, 7, 8, 9]},
return_train_score=True, scoring='f1')Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', DecisionTreeClassifier())])ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp', 'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare', 'sibsp', 'parch']
SimpleImputer(strategy='median')
['sex', 'embarked']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
DecisionTreeClassifier()
tree_cv_results = pd.DataFrame(grid_search.cv_results_)
(tree_cv_results[['params', 'mean_test_score', 'mean_train_score']]
.sort_values(by='mean_test_score', ascending=False)
.head(10))
| params | mean_test_score | mean_train_score | |
|---|---|---|---|
| 47 | {'model__criterion': 'entropy', 'model__max_de... | 0.737464 | 0.746546 |
| 4 | {'model__criterion': 'gini', 'model__max_depth... | 0.726778 | 0.752055 |
| 2 | {'model__criterion': 'gini', 'model__max_depth... | 0.721987 | 0.740337 |
| 46 | {'model__criterion': 'entropy', 'model__max_de... | 0.720758 | 0.741882 |
| 26 | {'model__criterion': 'gini', 'model__max_depth... | 0.718246 | 0.830027 |
| 42 | {'model__criterion': 'entropy', 'model__max_de... | 0.716765 | 0.731583 |
| 12 | {'model__criterion': 'gini', 'model__max_depth... | 0.711195 | 0.776762 |
| 3 | {'model__criterion': 'gini', 'model__max_depth... | 0.710254 | 0.736806 |
| 52 | {'model__criterion': 'entropy', 'model__max_de... | 0.710147 | 0.750812 |
| 76 | {'model__criterion': 'entropy', 'model__max_de... | 0.709438 | 0.854808 |
grid_search.best_params_
{'model__criterion': 'entropy',
'model__max_depth': 4,
'model__max_features': 9}
modelo = DecisionTreeClassifier(criterion='entropy',
max_depth=4,
max_features=8)
DecisionTree_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", modelo)])
decision_tree_model = DecisionTree_pipe.fit(x_train, y_train)
y_pred = decision_tree_model.predict(x_test)
summarize_classification(y_test, y_pred)
Test data count: 262
f1_score : 0.7653061224489796
accuracy_score : 0.8244274809160306
precision_score : 0.7731958762886598
recall_score : 0.7575757575757576
roc_auc_score : 0.8113032162111917
Regresion logistica
# cuando se usan pipelines se debe usar
# el nombre del paso y luego __ y el parametro
parameters = {'model__penalty': ['l1', 'l2'],
'model__C': [0.1, 0.4, 0.8, 1, 2, 5]}
modelo = LogisticRegression(solver='liblinear')
logistic_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", modelo)])
grid_search = GridSearchCV(logistic_pipe,
parameters, cv=3,
scoring='f1',
return_train_score=True)
grid_search.fit(x_train, y_train)
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age',
'fare',
'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex',
'embarked']),
('categoricas '
'ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
LogisticRegression(solver='liblinear'))]),
param_grid={'model__C': [0.1, 0.4, 0.8, 1, 2, 5],
'model__penalty': ['l1', 'l2']},
return_train_score=True, scoring='f1')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age',
'fare',
'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex',
'embarked']),
('categoricas '
'ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
LogisticRegression(solver='liblinear'))]),
param_grid={'model__C': [0.1, 0.4, 0.8, 1, 2, 5],
'model__penalty': ['l1', 'l2']},
return_train_score=True, scoring='f1')Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp',
'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model', LogisticRegression(solver='liblinear'))])ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare', 'sibsp', 'parch']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex', 'embarked']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare', 'sibsp', 'parch']
SimpleImputer(strategy='median')
['sex', 'embarked']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
LogisticRegression(solver='liblinear')
reg_log_cv_results = pd.DataFrame(grid_search.cv_results_)
(reg_log_cv_results[['params', 'mean_test_score', 'mean_train_score']]
.sort_values(by='mean_test_score', ascending=False)
.head(10))
| params | mean_test_score | mean_train_score | |
|---|---|---|---|
| 6 | {'model__C': 1, 'model__penalty': 'l1'} | 0.712230 | 0.711734 |
| 5 | {'model__C': 0.8, 'model__penalty': 'l2'} | 0.711346 | 0.713974 |
| 7 | {'model__C': 1, 'model__penalty': 'l2'} | 0.711346 | 0.714403 |
| 4 | {'model__C': 0.8, 'model__penalty': 'l1'} | 0.711247 | 0.710449 |
| 8 | {'model__C': 2, 'model__penalty': 'l1'} | 0.709520 | 0.711829 |
| 9 | {'model__C': 2, 'model__penalty': 'l2'} | 0.709520 | 0.713576 |
| 3 | {'model__C': 0.4, 'model__penalty': 'l2'} | 0.708792 | 0.713781 |
| 10 | {'model__C': 5, 'model__penalty': 'l1'} | 0.707759 | 0.714807 |
| 11 | {'model__C': 5, 'model__penalty': 'l2'} | 0.707759 | 0.714807 |
| 2 | {'model__C': 0.4, 'model__penalty': 'l1'} | 0.706930 | 0.708156 |
grid_search.best_params_
{'model__C': 1, 'model__penalty': 'l1'}
modelo = LogisticRegression(solver='liblinear',
C=0.4,
penalty='l2')
logistic_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", modelo)])
logistic_model = logistic_pipe.fit(x_train, y_train)
y_pred = logistic_model.predict(x_test)
summarize_classification(y_test, y_pred)
Test data count: 262
f1_score : 0.7346938775510204
accuracy_score : 0.8015267175572519
precision_score : 0.7422680412371134
recall_score : 0.7272727272727273
roc_auc_score : 0.7869492470719465
Final Evaluation Test
from sklearn.metrics import classification_report
from sklearn.metrics import PrecisionRecallDisplay
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.metrics import roc_curve
from sklearn.metrics import RocCurveDisplay
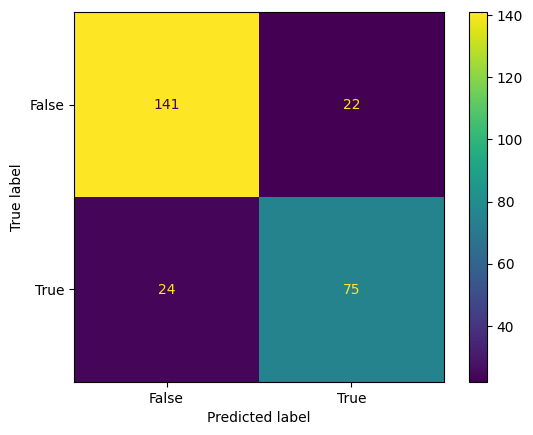
Decision Tree
y_pred = decision_tree_model.predict(x_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
False 0.85 0.87 0.86 163
True 0.77 0.76 0.77 99
accuracy 0.82 262
macro avg 0.81 0.81 0.81 262
weighted avg 0.82 0.82 0.82 262
ConfusionMatrixDisplay.from_predictions(y_test,y_pred);
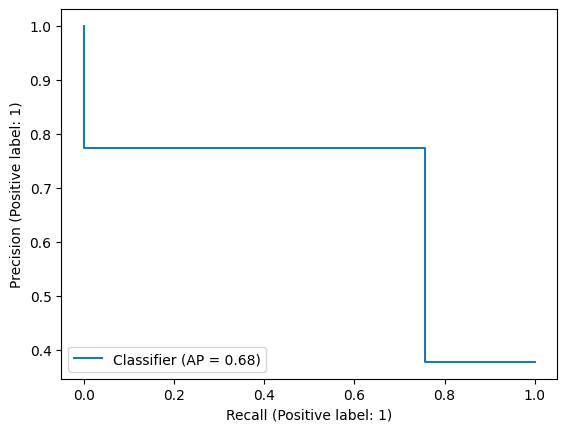
PrecisionRecallDisplay.from_predictions(y_test,y_pred);
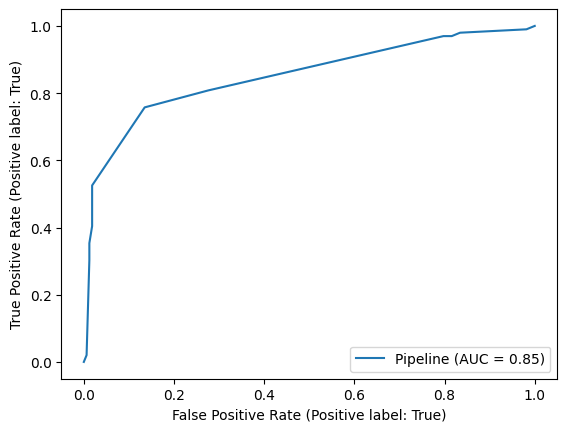
dt_plot = RocCurveDisplay.from_estimator(decision_tree_model, x_test, y_test)
plt.show()
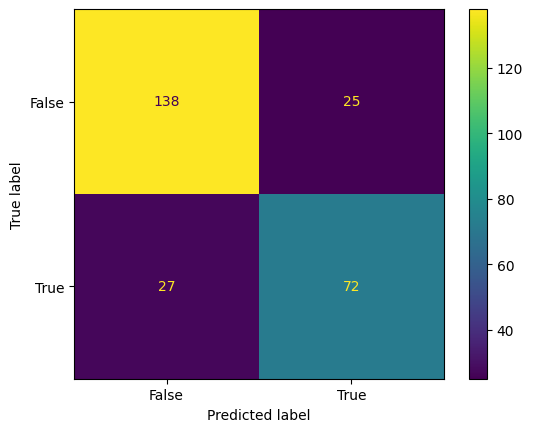
Regresion Logistica
y_pred = logistic_model.predict(x_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
False 0.84 0.85 0.84 163
True 0.74 0.73 0.73 99
accuracy 0.80 262
macro avg 0.79 0.79 0.79 262
weighted avg 0.80 0.80 0.80 262
ConfusionMatrixDisplay.from_predictions(y_test,y_pred);
PrecisionRecallDisplay.from_predictions(y_test,y_pred);
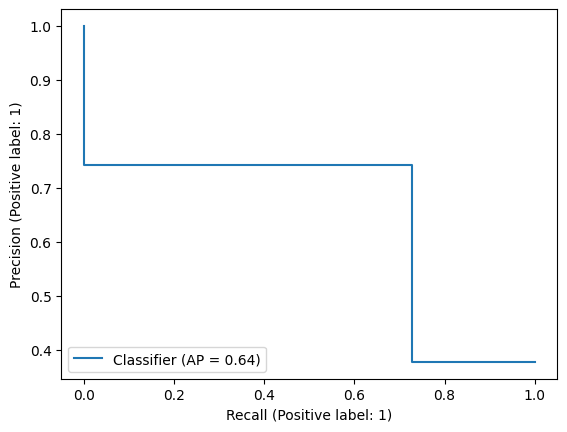
log_plot = RocCurveDisplay.from_estimator(logistic_model, x_test, y_test)
plt.show()
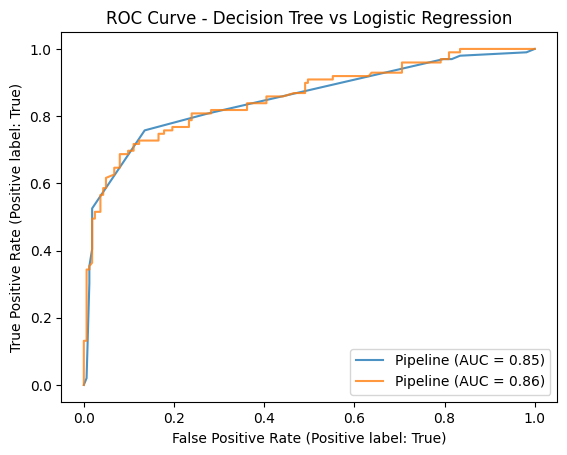
Comparacion modelos
ax = plt.gca()
dt_plot.plot(ax=ax, alpha=0.8)
log_plot.plot(ax=ax, alpha=0.8)
plt.title('ROC Curve - Decision Tree vs Logistic Regression')
plt.show()
Interpretacion del Modelo
Como mejor modelo se selecciona el Decision Tree, con los siguientes parametros:
{'criterion': 'entropy', 'max_depth': 4, 'max_features': 8}
dfFeatures = pd.DataFrame({'Features':decision_tree_model['preprocessor']
.get_feature_names_out(),
'Importances':decision_tree_model['model']
.feature_importances_})
dfFeatures.sort_values(by='Importances',ascending=False)
| Features | Importances | |
|---|---|---|
| 5 | categoricas__sex_male | 0.524125 |
| 9 | categoricas ordinales__pclass | 0.227958 |
| 1 | numericas__fare | 0.109974 |
| 0 | numericas__age | 0.080572 |
| 2 | numericas__sibsp | 0.042068 |
| 8 | categoricas__embarked_S | 0.015302 |
| 3 | numericas__parch | 0.000000 |
| 4 | categoricas__sex_female | 0.000000 |
| 6 | categoricas__embarked_C | 0.000000 |
| 7 | categoricas__embarked_Q | 0.000000 |
En base a estos resultados se puede concluir que las variables mas importantes para determinar si una persona sobrevivio o no son:'sex', 'pclass', 'age', 'fare'
x_train = x_train.drop(columns=['sibsp', 'parch', 'embarked'])
cols_numericas = ["age", "fare"]
cols_categoricas = ["sex"]
cols_categoricas_ord = ["pclass"]
numeric_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
])
categorical_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())])
categorical_ord_pipe = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())])
preprocessor = ColumnTransformer(
transformers=[
('numericas', numeric_pipe, cols_numericas),
('categoricas', categorical_pipe, cols_categoricas),
('categoricas ordinales', categorical_ord_pipe, cols_categoricas_ord)
])
modelo = DecisionTreeClassifier(criterion='entropy',
max_depth=4,
max_features=8)
DecisionTree_pipe = Pipeline(steps=[("preprocessor", preprocessor),
("model", modelo)])
DecisionTree_pipe.fit(x_train, y_train)
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
DecisionTreeClassifier(criterion='entropy', max_depth=4,
max_features=8))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
DecisionTreeClassifier(criterion='entropy', max_depth=4,
max_features=8))])ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare']
SimpleImputer(strategy='median')
['sex']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
DecisionTreeClassifier(criterion='entropy', max_depth=4, max_features=8)
x_test = x_test.drop(columns=['sibsp', 'parch', 'embarked'])
y_pred = DecisionTree_pipe.predict(x_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
False 0.85 0.88 0.86 163
True 0.78 0.74 0.76 99
accuracy 0.82 262
macro avg 0.82 0.81 0.81 262
weighted avg 0.82 0.82 0.82 262
Se obtienen resultados equivalentes con menos variables
Procesamiento y Modelo Final con scikit-learn
Luego realizar la seleccion del modelo final y sus hiperparametros, se procede a crear un pipeline completo de entrenamiento con todos los datos y prediccion.
En un proceso de Ciencia de datos se debe entrenar con todos los datos disponibles si es posible, para que el modelo final tenga la mayor cantidad de información posible. lo que evita que el modelo final tenga sobreajuste son los hiperparametros que se optimizaron en el paso anterior. Esto se hace en la aplicaciones reales, ya que normalmente los datos se van actualizando, por ejemplo en un sistema de clasificacion de anomalias, el modelo se va actualizando con los nuevos datos que van surgiendo y se va reentrenando con los datos historicos(pasado), para predecir datos presentes y futuros.
En este caso se va a usar el modelo de Decision Tree con los hiperparametros
{'criterion': 'entropy', 'max_depth': 4, 'max_features': 7}
Pipeline Final
Para entrenar el pipeline final se leen los datos limpios, solamente las columnas definidas anteriormente
columnas_base = ['sex', 'pclass', 'age', 'fare', 'survived']
titanic_df = pd.read_parquet('titanic_processed.parquet',
columns= columnas_base)
se dividen los datos en las variables de entrada y la variable de salida
X = titanic_df.drop('survived', axis='columns')
y = titanic_df['survived']
Se entrena el ultimo pipeline con todos los datos
DecisionTree_pipe.fit(X, y)
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
DecisionTreeClassifier(criterion='entropy', max_depth=4,
max_features=8))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot',
OrdinalEncoder())]),
['pclass'])])),
('model',
DecisionTreeClassifier(criterion='entropy', max_depth=4,
max_features=8))])ColumnTransformer(transformers=[('numericas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median'))]),
['age', 'fare']),
('categoricas',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder())]),
['sex']),
('categoricas ordinales',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='most_frequent')),
('onehot', OrdinalEncoder())]),
['pclass'])])['age', 'fare']
SimpleImputer(strategy='median')
['sex']
SimpleImputer(strategy='most_frequent')
OneHotEncoder()
['pclass']
SimpleImputer(strategy='most_frequent')
OrdinalEncoder()
DecisionTreeClassifier(criterion='entropy', max_depth=4, max_features=8)
Grabar el Modelo
from joblib import dump, load # libreria de serializacion
# grabar el modelo en un archivo
dump(DecisionTree_pipe, 'DecisionTree_pipe-titanic.joblib')
['DecisionTree_pipe-titanic.joblib']
from joblib import load
mi_modelo = load('DecisionTree_pipe-titanic.joblib')
x_test.head()
| pclass | sex | age | fare | |
|---|---|---|---|---|
| 782 | 3 | male | 65.0 | 7.7500 |
| 351 | 2 | male | 60.0 | 39.0000 |
| 1135 | 3 | male | NaN | 7.8958 |
| 73 | 1 | female | 22.0 | 151.5500 |
| 1243 | 3 | male | NaN | 7.2250 |
Puede verse que el valor de la primera fila de age es NaN, pero el modelo lo imputa
# hacer la prediccion solo de las primeras 5 filas de test
mi_modelo.predict(x_test.head())
array([False, False, False, True, False])
Referencias
Cheatsheet scikit-learn https://images.datacamp.com/image/upload/v1676302389/Marketing/Blog/Scikit-Learn_Cheat_Sheet.pdf
Phd. Jose R. Zapata