Por Jose R. Zapata
Ultima actualización: 24/Apr/2025

MLOps
MLOps, o Machine Learning Operations, es un conjunto de prácticas que integran el desarrollo de modelos de aprendizaje automático (ML) con las operaciones de producción, similar a DevOps pero específico para ML. Permite gestionar el ciclo de vida completo del ML de manera más eficiente, desde la recopilación de datos hasta la implementación y monitorización de los modelos. En esencia, MLOps busca automatizar y estandarizar los procesos de ML para que sean más confiables y productivos.
“MLOps aims to standardize the deployment and management of ML models alongside the operationalization of the ML pipeline. It supports the release, activation, monitoring, performance tracking, management, reuse, maintenance, and governance of ML artifacts” – Gartner
Algunos puntos clave sobre MLOps:
- Ciclo de vida del ML: MLOps abarca todo el ciclo de vida del ML, desde la recopilación y preparación de datos, hasta el entrenamiento, despliegue, monitorización y mantenimiento de los modelos.
- Integración de DevOps: MLOps se basa en los principios de DevOps, buscando automatizar y acelerar los procesos de desarrollo y despliegue.
- Automatización y estandarización: MLOps busca automatizar tareas repetitivas y estandarizar los procesos para facilitar la colaboración entre científicos de datos, ingenieros de software y otros profesionales.
- Beneficios: MLOps ayuda a reducir el tiempo de desarrollo, mejorar la calidad de los modelos, aumentar la productividad y facilitar la colaboración
Objetivos del MLOps
- Eficiencia y Agilidad: Acelerar el ciclo de vida del desarrollo de modelos, desde la concepción hasta la implementación y mantenimiento.
- Calidad y Fiabilidad: Asegurar que los modelos desplegados sean precisos y confiables a lo largo del tiempo.
- Escalabilidad: Facilitar el manejo de grandes volúmenes de datos y modelos complejos, asegurando que puedan crecer según las necesidades del negocio.
- Colaboración Interdisciplinaria: Fomentar la colaboración entre equipos de datos, científicos de datos, ingenieros de ML y operaciones de TI.
Desarrollo continuo
MLOps en un proceso de desarrollo continuo, donde los modelos y pipelines de machine learning se despliegan y gestionan de forma automática siguiendo las siguientes etapas de CI/CD/CT/CM
- Continuous Integration (CI) Se realizan pruebas de integración continua para asegurar que el código cumpla con las reglas de calidad.
- Continuous Delivery (CD) Se despliega el modelo de machine learning en el sistema de predicción.
- Continuous Training (CT) Se re entrena automáticamente el modelo de machine learning para ser desplegado.
- Continuous Monitoring (CM) Se monitorean en producción los datos y el desempeño del modelo.
El CT/CM son procesos específicos del MLOps a distinción del desarrollo de software, que solo requiere en forma general CI/CD.
Evolución de MLOps hacia Pipelines FTI (Feature / Training/Inference)
Antes de llegar a la arquitectura basada en pipelines FTI que permite modularidad, flexibilidad y un desarrollo incremental.

La búsqueda de una arquitectura de MLOps a pasado por diferentes etapas y se han generado multiples propuestas por empresas como Google, Databricks, Microsoft, entre otros.
Pre MLOps

Machine Learning en Monolito (Batch)
Desventajas de Monolitos
- Dificultad de Mantenimiento: Un monolito puede volverse difícil de mantener y escalar, especialmente cuando el código se vuelve más complejo.
- Modularidad: Los monolitos suelen ser menos modulares, lo que dificulta la reutilización de componentes y la separación de responsabilidades. No pueden escalarse ni implementarse de forma independiente en hardware diferente (p. ej., CPU para ingeniería de características, GPU para entrenamiento de modelos).
- Dificultad de Pruebas: Los monolitos suelen ser difíciles de probar, ya que no pueden ser desplegados de forma independiente y su comportamiento puede ser difícil de predecir.
- Costo de Operación: Los monolitos suelen tener un mayor costo de operación, ya que requieren más recursos y mantenimiento.
- Tiempo de Despliegue: Los despliegues de monolitos pueden ser más lentos y complejos, lo que reduce la velocidad de la entrega.
- Vinculación de Componentes: Los monolitos vinculan estrechamente la ejecución de la ingeniería de características, el entrenamiento de modelos y los pasos de inferencia, ejecutándolos simultáneamente.
Arquitecturas de MLOps
Grandes empresas como Google, Microsoft, Databricks y Amazon han desarrollado arquitecturas de MLOps que permiten desplegar y gestionar pipelines de machine learning.
En Google proponen un arquitectura de MLOps que permite desplegar y gestionar pipelines de machine learning, y esta dividido en 3 niveles de desarrollo:
- Nivel 0 (POC): Proceso manual
- Nivel 1: Proceso automatizado
- Nivel 2: Automatización de un pipeline de CI/CD
Google - Nivel 0 de MLOps (POC): Proceso manual

Google - Nivel 1 de MLOps (Prototipo): Proceso automatizado

Google - Nivel 2 de MLOps (MVP): Automatización de un pipeline de CI/CD

Estados del proceso de CI/CD automatizado en un pipeline de ML

Databricks
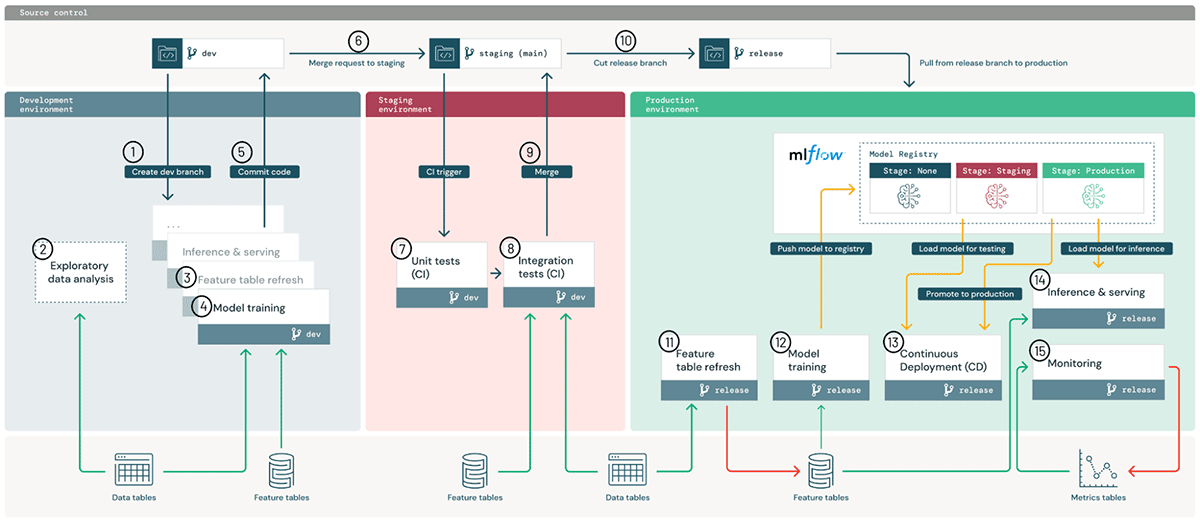
Desventajas de las Grandes Arquitecturas
- Modelos excesivamente complejos
- Arquitecturas con muchos componentes
- Se asemeja al modelo de desarrollo en cascada y no al iterativo
- Los pipelines de datos y de train están unidos en muchos casos y se asemejan más a los monolitos
Arquitectura Feature / Train / Inference Pipelines (FTI)
Es una arquitectura que permite desplegar y gestionar pipelines de machine learning de manera más eficiente. Esta arquitectura es propuesta por Jim Dowling, y presentada en:
- From MLOps to ML Systems with Feature/Training/Inference Pipelines
- Building Machine Learning Systems with a Feature Store - Jim Dowling

Ventajas de la arquitectura FTI
La arquitectura FTI ofrece varias ventajas clave que la convierten en un enfoque estándar de la industria para el desarrollo de sistemas de aprendizaje automático:
- Modularidad: Cada pipeline (Feature,Train e Inference) es independiente. Esto permite desarrollarlas, probarlas y optimizarlas por separado. Por ejemplo, se puede escalar el Feature Pipeline para gestionar transformaciones masivas de datos sin afectar los pipelines de Train o Inference.
- Reutilización: Las features almacenadas en un feature store pueden reutilizarse en diferentes modelos y proyectos de aprendizaje automático, lo que reduce la redundancia. De igual forma, los modelos entrenados guardados en un model registry pueden implementarse en múltiples entornos con un mínimo esfuerzo.
- Consistencia: Al garantizar que se utilicen las mismas features durante el train y la inference, la arquitectura elimina el riesgo de data leak y garantiza predicciones precisas.
- Escalabilidad: Cada pipeline puede escalar de forma independiente. El Feature Pipeline puede aprovechar sistemas distribuidos como Spark o Dask para procesar grandes conjuntos de datos, mientras que el Inference Pipeline puede usar Kubernetes para gestionar un alto rendimiento de predicción.
- Reproducibilidad: la arquitectura fomenta el registro y el control de versiones en cada pipeline lo que facilita la auditoría y la reproducción de resultados.
Transformaciones de los datos
También es importante entender la division de las transformaciones de datos:
- Model Independent: Transformaciones de los datos que no dependen del modelo, Por ejemplo: eliminar duplicados, convertir datos en embeddings, agregar información (Promedios, desviación, dispersión, etc), eliminar columnas sin información, limpieza de texto, etc.
- Model Dependent: Transformaciones de los datos que dependen del modelo, Por ejemplo: escalado, normalización, imputación, codificación de variables categoricas, etc.
- On-demand transformations: Transformaciones de los datos que se ejecutan solo cuando se necesita, Por ejemplo: transformar los datos nuevos para realizar predicciones.

FTI Pipelines
Los pipelines de FTI son:
- Feature Pipeline: Toma los datos de las fuentes originales y los transforma en features
- Training Pipeline: Toma los features y los transforma en un modelo entrenado
- Inference Pipeline: Toma el modelo y los datos nuevos y realiza predicciones
Feature pipeline
- E: Extract
- V: Validate
- A: Aggregate
- C: Compress
- MIT: Model-Independent Transformation
No es necesario ejecutar todos los pasos, solo los que son necesarios para el entrenamiento.
Training pipeline
- SFJ: Select+Filter+Join
- MDT: Model Dependent Transformation
- T: Training
- V: Validation
Inference pipeline - Batch
- R: Read Data and Load model from model registry
- MDT: Model Dependent Transformation
- P: Predict
Inference pipeline - Online
- PR: Prediction Request
- R: Read Data and Load model from model registry
- T: Transforms on-demand
- M: Merge (precomputed and on-demand features)
- MDT: Model Dependent Transformation
- P: Predict with the model
- PS: Prediction(s)
Referencias
- From MLOps to ML Systems with Feature/Training/Inference Pipelines
- Building Machine Learning Systems with a Feature Store - Jim Dowling
- MLOps: canalizaciones de automatización y entrega continua en el aprendizaje automático
- MLOps principles
- https://blog.zenml.io/data-centric-mlops/
- https://neptune.ai/blog/mlops
- https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#mlops_level_1_ml_pipeline_automation